ヒストグラムの作成
Axesオブジェクトの hist() メソッドを使うと、ヒストグラムを描くことができます。以下のサンプルコードでは、男性の身長の疑似統計データを作成してヒストグラムで可視化しています。
# MATPLOTLIB_HISTOGRAM_01
# In[1]
# 男性の身長ヒストグラム
# NumPyとmatplotlib.pyplotをインポート
import numpy as np
import matplotlib.pyplot as plt
# Figureを作成
fig = plt.figure()
# グリッド線の表示
plt.style.use("ggplot")
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
# Axesのタイトルと軸ラベルを設定する関数
def set_title_label():
ax.set_title("Male Height Distribution", fontsize=16)
ax.set_xlabel("Height", fontsize=16)
ax.set_ylabel("Frequency", fontsize=16)
# 正規分布にしたがうデータ(男性の平均身長)を作成
mu = 171
sigma = 5.7
np.random.seed(0)
x = np.random.normal(mu, sigma, size=1000)
# Axesにヒストグラムを描画
set_title_label()
ax.hist(x, color="blue")
# グラフを描画
plt.show()

コード HISTOGRAM_01-1 の解説です。疑似データの作成には、numpy.random の normal()関数を使用しています。normal() は第 1 引数と第 2 引数で指定した平均値と標準偏差をもつ正規分布にしたがう乱数を返します。また、size でデータの個数を指定しています。上のサンプルコードでは最初に
# 平均値と標準偏差の設定 mu = 171 sigma = 5.7
と記述して平均値と標準偏差の値を明示しています。値を直接 normal() の引数に記述すればコードの行数は節約できますが、このように書いておけば、このデータを書き換えることによって異なる分布が描けることがすぐにわかります。
次に numpy.random の seed()関数で乱数の seed値(種)を固定して、乱数ジェネレータを初期化しています:
# 乱数ジェネレータの初期化 np.random.seed(0)
この記述によって、上のサンプルコードをコピーしたユーザーは同じデータを再現することができます(グラフも同じ形になるはずです)。
先ほど設定した 平均値 mu と標準偏差 sigma, データの個数 1000 を normal()関数に渡してデータを作成します:
# 正規分布にしたがうデータ(男性の身長データ)を作成 x = np.random.normal(mu, sigma, size = 1000)
Axesオブジェクトの hist()メソッドを使って、ヒストグラムを描きます(グラフの色は青に設定):
# Axesにヒストグラムを描画 ax.hist(x, color = "blue")
binの幅を調整する
hist()メソッドのデフォルト設定では、bin (棒) 同士の間に隙間がなく、あまり見栄えがよくありません。そこで bin の幅を引数 rwidth で調整してみます。
# In[2] # Axesを初期化 ax.cla() # Axesにヒストグラムを描画 set_title_label() ax.hist(x, rwidth=0.9, color="blue") # グラフを再表示 display(fig)
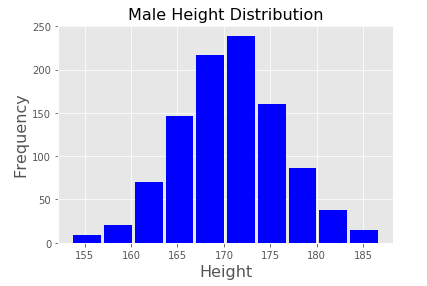
rwidth はデフォルトの幅を 1 とする相対的な値を渡します。rwidth = 0.9 ならデフォルト値の 90% の幅が指定されたことになります。
データを正規化して相対度数を表示する
デフォルト設定ではヒストグラムの縦軸は階級幅に入るデータ数を表しますが、このままではデータ数の異なる他のデータと比較することができません。引数 density に True を渡すとデータが正規化され、ヒストグラムの縦軸は相対度数を表すようになります:
# In[3] # Axesを初期化 ax.cla() # Axesにヒストグラムを描画 set_title_label() ax.hist(x, rwidth=0.9, color="blue", density=True) # グラフを再表示 display(fig)
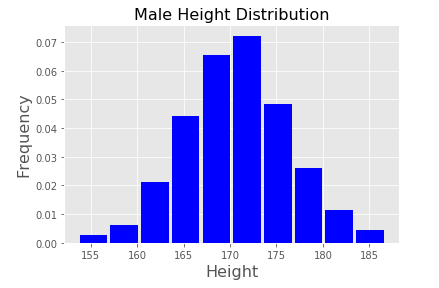
以前は正規化する引数として normed がありましたが、現在では非推奨となり(今でも使えることは使えますが、いずれ廃止される可能性が高いです)、代わりに density を使用するように勧められています。上のグラフは、すべての bin の面積を足し合わせると 1 になるように調整されています (個々の bin の面積は [階級幅] × [頻度])。
複数のヒストグラムを重ねる
Axesオブジェクトの hist()メソッドに繰り返し引数が渡されると、Axes に複数のヒストグラムが重ねて表示されます。今度は男女の身長の疑似統計データを作成してヒストグラムを描いてみましょう。
# PYTHON_MATPLOTLIB_HISTOGRAM_02
# In[1]
# 身長ヒストグラム
# NumPyとmatplotlib.pyplotをインポート
import numpy as np
import matplotlib.pyplot as plt
# Figureを作成
fig = plt.figure()
# グリッド線の表示
plt.style.use("ggplot")
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
# Axesのタイトルの設定
ax.set_title("Height Distribution", fontsize=16)
# 軸ラベルの設定
ax.set_xlabel("Height", fontsize=16)
ax.set_ylabel("Frequency", fontsize=16)
# 男性(male)の身長の平均値と標準偏差の設定
mu_m = 171
sigma_m = 5.7
# 女性(female)の身長の平均値と標準偏差の設定
mu_f = 159
sigma_f = 5.2
# 乱数ジェネレータの初期化
np.random.seed(0)
# 正規分布にしたがう身長データを作成
x = np.random.normal(mu_m, sigma_m, size=1000)
y = np.random.normal(mu_f, sigma_f, size=1000)
# Axesにヒストグラムを描画
ax.hist(x, rwidth=0.9, color="blue",
label="male", density=True)
ax.hist(y, rwidth=0.9, color="red",
label="female", alpha=0.6, density=True)
ax.legend(loc="upper left")
# グラフを描画
plt.show()
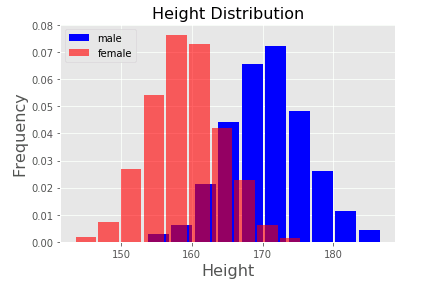
最初のサンプルとほぼ同じ構造のコードですが、今回はそれぞれのヒストグラムが何を表しているのかを識別するためにデータの凡例(ラベル)を添えています。凡例として表示する文字は hist メソッドの label 引数で指定し、その表示位置は legend()メソッドの loc 引数に渡します。サンプルコードでは “upper left” (左上) に表示させています。ヒストグラムが重なると後ろのデータが見えなくなってしまうので、手前に表示される女性のヒストグラムは alpha 引数を指定して半透明にしてあります。
numpy.histogram()
NumPy でヒストグラムのデータを作成したい場合は numpy.histogram() を使います。この関数は配列を受け取って、度数と階級境界 (bin) を返します。例として、成人男性 100 名分の体重データについて、10kg ごとの階級別頻度 (ヒストグラム) を作成してみます。
# NUMPY_HISTOGRAM
# In[1]
import numpy as np
# 成人男性の体重の平均値と標準偏差
mu_w = 62.3
sigma_w = 8.52
# 疑似乱数ジェネレータを初期化
np.random.seed(0)
# 成人男性の体重分布
w = np.random.normal(mu_w, sigma_w, size=100)
# 度数とビンの境界
hist_values, hist_bins = np.histogram(w, bins=[30, 40, 50, 60, 70, 80, 90])
print("度数: {}".format(hist_values))
print("階級の境界: {}".format(hist_bins))
# 度数: [ 0 8 30 41 19 2]
# 階級の境界: [30 40 50 60 70 80 90]
上のコードでは、bins に階級境界リストを渡しています。
この引数を省略すると、第 1 引数で渡したデータ区間 (最大値-最小値) を 10 等分します。bins に整数 n を渡した場合はデータ区間を n 等分します。
numpy.histogram() で作成したデータを可視化するときは、Axes.bar() に度数と階級値 (階級を代表する値) を渡します。各区間の中央値を階級値として設定してみましょう。
# In[2]
# 階級値
hist_bins_mid = (hist_bins[1:] + hist_bins[:-1]) / 2
print("階級値: {}".format(hist_bins_mid))
# 階級値: [35. 45. 55. 65. 75. 85.]
Axes.bar() でヒストグラムをプロットします。
# In[3]
import matplotlib.pyplot as plt
# FigureとAxes
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_xlim(30, 90)
ax.set_title("Weight Distribution", fontsize=16)
ax.set_xlabel("Weight", fontsize=16)
ax.set_ylabel("Frequency", fontsize=16)
# ヒストグラムをプロット
ax.bar(hist_bins_mid, hist_values, width=8, edgecolor="black")
plt.show()
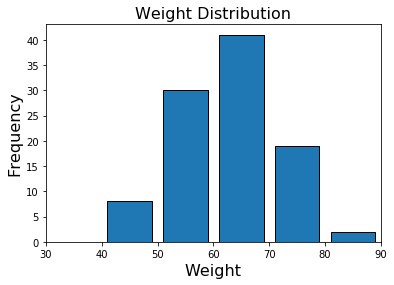
コメント
下記は誤植と思われますので、ご確認ください。
HISTOGRAM_01-1プログラムの中に、np.random.seed(0) がありません。
HISTOGRAM_01-2 と -3 は、HISTOGRAM_01-1の Axes を再利用していると思われます。そうであれば冒頭に ax.cla() が必要ですが、その時はタイトルや軸ラベルはクリアされます。HISTOGRAM_01-2 と -3 のプログラムと実行結果のご確認をお願いいたします。
大変申し訳ありません。
確かにコードに不備がありました。
np.random.seed(0)を追加しました。
タイトルと軸ラベルの設定は関数にまとめておきました。
ついでに、旧式のコード番号を新式番号に書き直しておきました。
(コードの再利用がわかるようにIn[1], In[2], … となっています)