
MobileNetV2でCNN画像分類
機械学習をやっていると、
「データが少なすぎて、モデルの汎化性能がちっとも向上しない!」
という悩みはつきものです。特に画像分類なんて、あるカテゴリーの画像を何千枚、何万枚も集めるなんて、どれだけの費用と時間がかかるのか、考えるだけで絶望的になります。
仮に何らかの方法で必要な資料を集めることができたとしても、数万枚のデータを読み込ませて CNN を訓練するには、Google Colab の T4 GPU を使ったとしても、めちゃくちゃ時間がかかります。
転移学習とは?
そこで、今回は少ないリソースで、効率よくモデルを訓練できる、夢のような手法、転移学習 について紹介します。転移学習をざっくり説明すると、
「他の人が一生懸命訓練したモデルをちょっとばかり拝借して、自分のモデルに組み込んで楽をしよう」
という手法です。もう少しきちんと説明すると、あるタスクで学習した知識を、関連するタスクに適用する手法です。今回は画像分類で転移学習を活用しますが、転移学習は以下のような分野でも活用されています。
・自然言語処理:大規模テキストコーパスで学習した言語モデルを、特定分野(医療、法律など)のテキスト分析に適用する
・音声認識:一般的な音声認識モデルを、特定のアクセントやノイズ環境での音声認識に特化させる
ImageNetで訓練されたMobileNetV2を画像分類に活用します
今回、紹介する MobileNetV2 は、ImageNet(動物、植物、建物、乗り物、日用品など、日常生活のあらゆる物体が階層的に分類されたデータセット)を用いて、基本的な画像特徴(エッジ、テクスチャ、形状など)を事前学習しています。このため、基礎的な特徴抽出部分を再学習する必要がなく、少ないデータセット(今回のような1000枚程度の画像)でも、モデルの性能を迅速に向上させることが可能です。
それでは、さっそく、TensorFlow の CNN 画像分類で MobileNetV2 の威力を実感してもらいます。まずは必要なライブラリをまとめて読み込んでおきます。
# TensorFlow CNN画像分類 MobileNetV2 組み込みモデル # In[1] import tensorflow as tf from tensorflow.keras import layers, models import tensorflow_datasets as tfds import matplotlib.pyplot as plt
次に tensorflow_datasetsから、犬猫の画像と、正解ラベルがセットで格納されたデータを読み込みます。
# In[2]
# データセットの読み込み
# as_supervised=Trueで教師あり学習用の(input,label)形式で取得する
dataset, info = tfds.load('cats_vs_dogs', split=['train'], with_info=True, as_supervised=True)
full_dataset = dataset[0]
‘cats_vs_dogs’ は機械学習用のデータとしては比較的軽量ですが、それでも総計23262枚もの画像データを含むので、Google Colab の T4 GPU を使ったとしても、訓練に数分間かかります。練習段階で訓練の度に待ち時間があると鬱陶しいですし、今回の記事の目的は「学習済みモデルを援用すると、どれぐらい早くトレーニングできるか」を示すのが目的なので、敢えて少ないデータを扱います。というわけで、1000 個だけ抜き出します。
# In[3] # サブセットの作成 subset_size = 1000 subset_dataset = full_dataset.take(subset_size)
一部のデータを抜き出しているので、犬と猫、それぞれ同程度の画像が含まれているか心配ですよね。もちろん、天下の TensorFlow が用意した学習データなので、そのような点でぬかりはないと思いますが、心配性の私としては、こういう細かいところがどうしても気になってしまうので、念のために確認しておきます。
# In[4]
# 訓練用データのラベル分布を確認
labels = [label.numpy() for _, label in subset_dataset]
print("Cats: ", labels.count(0))
print("Dogs: ", labels.count(1))
# Cats: 515
# Dogs: 485
大丈夫そうですね。以下のコードでデータの概要が確認できます。
# In[5] # cats_vs_dogsの情報を表示 print(info) # 実行結果は長いので省略
実行結果には
'train': <SplitInfo num_examples=23262, num_shards=16>
とありますが、なぜ画像枚数が 23262 という中途半端な数字なのか気になりませんか?
info に含まれる “There are 1738 corrupted images that are dropped.” という一文に注目してください。 本来、’cats_vs_dogs’ には 25,000 枚のデータが用意されていましたが、画像形式が正しくなかったり、画像ファイルのヘッダーやメタデータが破損していたりしているので、データセットの読み込み時に 1738 枚が自動的に破棄されたということです(23,262 + 1,738 = 25,000)。まあ、知っていても知らなくても、どうでもいいような情報なので、本題に戻りましょう。訓練用とテスト用のデータ数を確認しておきます。
# In[6] # データセットのシャッフル # シャッフルバッファサイズを指定(全データ数以上でデータが完全にシャッフルされる) subset_dataset = subset_dataset.shuffle(buffer_size=subset_size, seed=42) # 訓練データセットとテストデータセットの分割(8:2の比率) train_size = int(subset_size * 0.8) # 訓練データは800枚 test_size = subset_size - train_size # 残りのテストデータは200枚 # データセットの分割 train_dataset = subset_dataset.take(train_size) # 訓練データ test_dataset = subset_dataset.skip(train_size) # テストデータ print(train_size, test_size) # 800 200
cats_vs_dogs の画像はサイズが揃っていません(”画像分類あるある” ですね!)。面倒ですがきちんと前処理をしておきましょう。画像を適当なサイズに揃えて、正規化しておきます。
# In[7]
# 画像のサイズ
IMG_SIZE = 128
# 前処理関数(リサイズと正規化)
def preprocess(image, label):
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
image = image / 255.0 # 正規化
return image, label
1000枚でも、フルバッチで学習させるのはさすがに大変なので、トレーニング用データとテスト用データをバッチ化しておきます。
# In[8] # バッチサイズを32に指定 # トレーニングデータが800サンプル、バッチサイズが32なので、 # トレーニングデータのバッチ数は800/32=25 BATCH_SIZE = 32 # トレーニング用データとテスト用データをバッチ化 # 効率的なデータロードのために、prefetch(tf.data.AUTOTUNE)を追加しておく train_dataset = train_dataset.map(preprocess).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE) test_dataset = test_dataset.map(preprocess).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
ベースモデルとして、MobileNetV2 を読み込んで、モデルを構築します。ベースモデルの下には、プーリング層と全結合層だけ加えます。畳み込み層は必要ありません。
# In[9]
base_model = tf.keras.applications.MobileNetV2(input_shape=(IMG_SIZE, IMG_SIZE, 3),
include_top=False,
weights='imagenet')
# 事前学習済み部分を固定する(再学習させない)
base_model.trainable = False
# モデルを構築
model = models.Sequential([
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
# モデルの概要を表示
model.summary()
| Layer (type) | Output Shape | Param # |
|---|---|---|
| mobilenetv2_1.00_128 (Functional) | (None, 4, 4, 1280) | 2,257,984 |
| global_average_pooling2d(GlobalAveragePooling2D) | (None, 1280) | 0 |
| dense (Dense) | (None, 128) | 163,968 |
| dense_1 (Dense) | (None, 1) | 129 |
モデルをコンパイルします。
# In[10]
# モデルのコンパイル
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
# モデルのトレーニング
EPOCHS = 10
history = model.fit(train_dataset,
validation_data=test_dataset,
epochs=EPOCHS)
# 学習の進行状況をプロット
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# モデルの評価
loss, accuracy = model.evaluate(test_dataset)
print(f"Test Loss: {loss}")
print(f"Test Accuracy: {accuracy}")
# Test Loss: 0.00033416482619941235
# Test Accuracy: 1.0
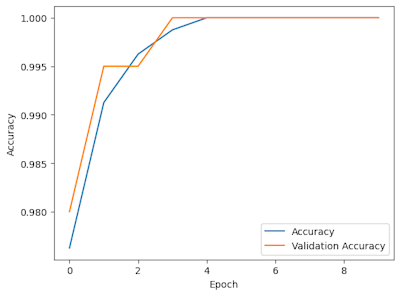
僅か 1000 枚の画像しか使用していないにも関わらず、5 Epoch × 25 = 125 step で Validation Accuracy が 1.000 に達しています。画像分類としては驚異的な速さです。これがどれだけ速いか知るには、普段やるみたいに、畳み込み層とプーリング層をごりごり積んで実行してみたください。たとえば、以下のコードでは 10 Epoch 学習させても、Validation Accuracy は 0.75 までしか到達しません。実行結果は省略しますが、興味のある人は試してみてください。
# In[11]
# MobileNetV2を使用しない場合のコード
# モデルの構築
model = models.Sequential([
# 畳み込み層とプーリング層
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 全結合層
layers.Flatten(),
layers.Dense(128, activation='relu'),
# 2クラス分類のためシグモイド関数を使用
layers.Dense(1, activation='sigmoid')
])
# モデルのコンパイル
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 学習の実行
EPOCHS = 10
history = model.fit(train_dataset,
validation_data=test_dataset,
epochs=EPOCHS)
# 学習の進行状況をプロット
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
コメント