
pandas.read_excel()
pandas.read_excel() を使うと、Excel ファイルをデータフレームに読み込むことができます。この関数は xls と xlsx ファイルをサポートします。xls は Excel 2003 以前、xlsx は Excel 2007 以降のバージョンで使用されている Excel ファイルの形式です。データフレームを Excel ファイルへ書き込む方法については以下の記事を参照してください。
Excelファイルを読み込む
当サイトの上位サイト atelierkobato.com から NPSAO_03.xlsx を読み込んでデータフレームに格納してみましょう。このファイルには氏名 (Name)、ふりがな (Phonetic)、性別 (Sex)、年齢 (Age)、職業 (Occupation) の 5 項目の疑似個人情報が 5 名ずつ 3 枚のシートに収められています。
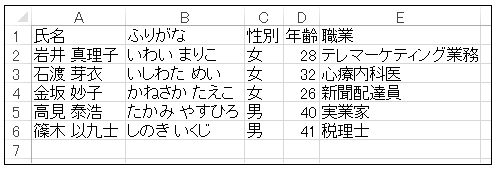
キーワード引数を何も指定しないと、1 番目のシートだけが読み込まれます。
# PANDAS_READ_EXCEL # In[1] import numpy as np import pandas as pd url = "https://atelierkobato.com/wp-content/uploads/NPSAO_03.xlsx" data = pd.read_excel(url) data
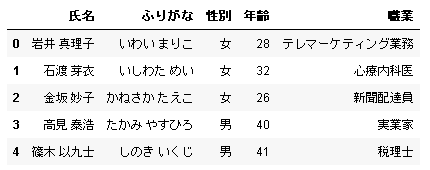
デフォルト設定ではシートの 1 行目は列ラベルとして読み込まれ、行ラベルには自動的に数字が割り当てられます。氏名 (シートの左端の列) を行ラベルに設定する場合は index_col=0 を指定します。
# In[2] data = pd.read_excel(url, index_col=0) data
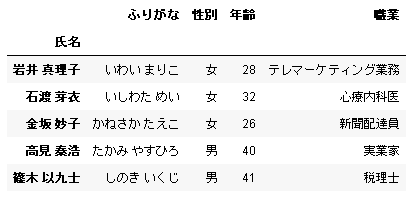
sheet_name で読み込むシートを指定できます。
2 番目のシートを選択する場合は sheet_name = 1 です。
# In[3] data = pd.read_excel(url, index_col=0, sheet_name=1) data
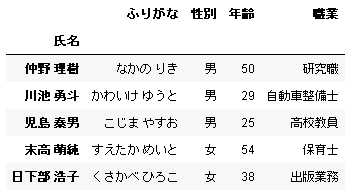
sheet_name にシート名を渡して読み込むこともできます。NPSAO_03.xlsx ファイルの各シートには List1, List2, List3 という名前が付けられています。List3 を読み込んでみましょう。
# In[4] data = pd.read_excel(url, index_col=0, sheet_name="List3") data
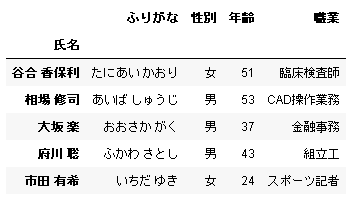
複数シートをまとめて読み込んだ場合、シート番号を key、データフレームを値とする OrderedDict が返ってきます。
# In[5] data = pd.read_excel(url, index_col=0, sheet_name=[0,2]) data

sheet_name に None を渡した場合はすべてのシートを読み込みます。
usecols で読み込む列番号を指定する
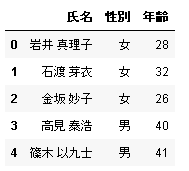
usecols に整数リストを渡すと、リストの要素に対応する列だけ読み込むことができます。たとえば、NPSAO_03.xlsx の最初のシートの 1, 3, 4 列目 (氏名、性別、年齢) を読み込む場合は次のように記述します。
# PANDAS_READ_EXCEL_USECOLS # In[1] url = "https://atelierkobato.com/wp-content/uploads/NPSAO_03.xlsx" data = pd.read_excel(url, usecols=[0,2,3]) data
skiprows で読み込まない行番号を指定する
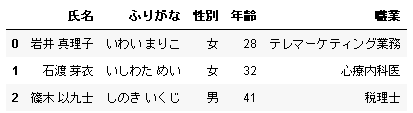
skiprows でシートから読み込まない行を指定できます。たとえば、シートの 4 行目と 5 行目を読み込まない場合は skiprows = [3, 4] です。
# PANDAS_READ_EXCEL_SKIPROWS # In[1] url = "https://atelierkobato.com/wp-content/uploads/NPSAO_03.xlsx" data = pd.read_excel(url, skiprows=[3,4]) data
空白セルの処理
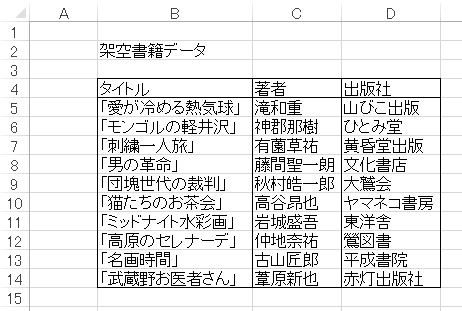
実際には、Excel のワークシートには様々な形でデータが格納されているので、pandas がデータをどのように取り込むかを知っておかないと戸惑うこともあります。たとえば、atelierkobato.com の book.xlsx には架空書籍のタイトル、著者、出版社が次のような形で記載されています。
オプション引数なしで読み込むと失敗します:
# PANDAS_READ_EXCEL_BLANK # In[1] url = "https://atelierkobato.com/wp-content/uploads/book.xlsx" data = pd.read_excel(url) data
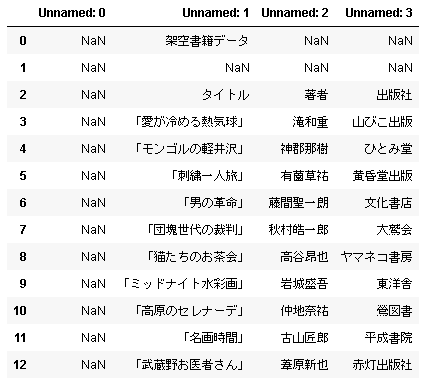
デフォルトでは自動的に最初の行をヘッダー (見出し) に設定しますが、ワークシートの一番上の行が空白になっているので、Unnamed:x という列ラベルが勝手に割り当てられてしまいます。
NaN が並ぶ列はシートの左端の空白の列に対応しています。
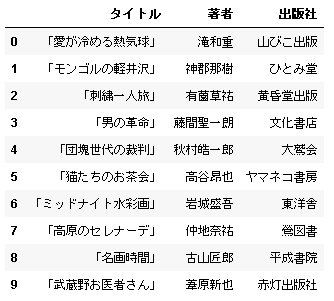
Excel では表が空白のセルに囲まれていることはよくありますが、header でヘッダー、usecols で読み込む列を指定すると問題は解決します。
# In[2] data = pd.read_excel(url, header=3, usecols=[1,2,3]) data
コメント
EXCEL_01-5 プログラムの実行結果で、0ページの末尾が改行されずに下記のようになります。
{0: ふりがな 性別 年齢 職業
氏名
・・・・・・・・・・・・・・・・・・・・・・・・・・
・・・・・・・・・・・・・・・・・・・・・・・・・・
・・・・・・・・・・・・・・・・・・・・・・・税理士, 2: ふりがな 性別 年齢 職業
氏名
・・・・・・・・・・・・・・・・・・・・・・・・・・
・・・・・・・・・・・・・・・・・・・・・・・・・・
・・・・・・・・・・・・・・・・・・・・・スポーツ記者}
Excel ファイルの読み込み時に使える、多数のオプション引数の使い方を教えていただき、ありがとうございました。
コードの動作を再確認したところ、Jupyter Notebook では問題なく改行されましたが、おっしゃるように Google Colab では改行がうまくいきませんでした。pprint.pprint() で実行結果を出力すると解決すると思います。以下のコードを試してみてください。
――――――――――――――――――――――――――――――
from pprint import pprint
data = pd.read_excel(url, index_col=0, sheet_name=[0,2])
pprint(data)
――――――――――――――――――――――――――――――
pprint( ) で「改行」がうまく処理されることを確認しました。
ありがとうございました。