
ニューラルネットワークの構造
生物のニューラルネットワークをコンピュータ上に模倣したモデルを人工ニューラルネットワーク(Artificial Neural Network)とよびます。機械学習の分野では「人工」を省略するのが一般的なので、当講座でも以降は単に ニューラルネットワーク(Neural Network)と記述します。
ニューラルネットワークは ニューロン を入力層、中間層(隠れ層)、出力層の順に層状に並べて構築します。
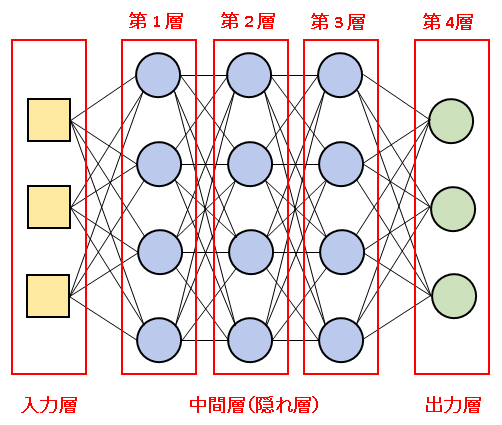
入力層は信号をニューラルネットワークに送ります。出力層はニューラルネットワークから信号を出力します。入力層と出力層の間には複数の中間層(隠れ層)を並べます。そして、入力層から出力層まで、第0層、第1層、第2層 … というように順序づけることにします(入力層を第1層とする方式もありますが、当サイトでは中間層から第1層と数える方式を採用します)。また、入力信号が上から下へと流れていくイメージで、ある層から見て入力層に近い層を上の層、出力層に近い層を下の層とよぶことにします。
ある1つのニューロンからの信号は、次の層のすべてのニューロンに重みをつけて渡されます。同じ層にあるニューロン同士では信号のやりとりは行われません。
ニューラルネットワークから 2つの層を選んで、上の層を $a$ 層、下の層を $b$ 層とします。簡単のために、$a$ 層・$b$ 層ともに 2個のニューロンで構成されているとします。
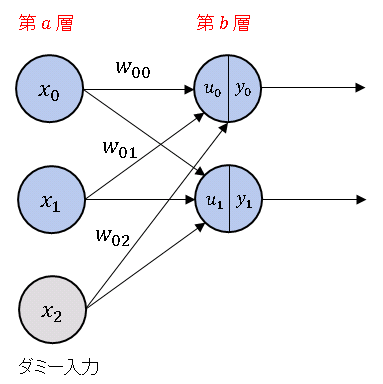
$x_0,\ x_1$ は $b$ 層が $a$ 層から受け取る入力です。$x_2$ はダミー入力(疑似信号)で、常に 1 の値をとります。$w_{ji}$ は $b$ 層の $j$ 番目のニューロンが $a$ 層の $i$ 番目のニューロンから受け取る信号に掛かる重みを表しています(下図参照)。
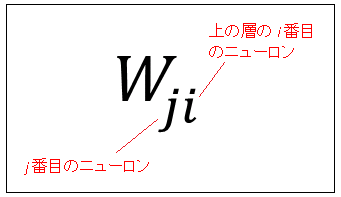
たとえば、$w_{01}$ は「$b$ 層の 0 番目のニューロンが $a$ 層の 1 番目のニューロンから受け取る信号に掛かる重み」を表しています。
$u_j$ は $b$ 層の $j$ 番目のニューロンの入力総和を表します。
たとえば、$u_0$ は $b$ 層の 0 番目のニューロンの入力総和であり、$a$ 層のすべてのニューロンからの入力とダミー入力の線形結合で表されます。
\[u_0=w_{00}x_0+w_{01}x_1+w_{02}x_2\tag{1}\]
同様に $u_1$ は $b$ 層の 1 番目のニューロンの入力総和です。
\[u_1=w_{10}x_0+w_{11}x_1+w_{12}x_2\tag{2}\]
(1) と (2) は行列形式で
\[\begin{bmatrix}u_0\\u_1\end{bmatrix}=\begin{bmatrix}w_{00} & w_{01} & w_{02}\\
w_{10} & w_{11} &
w_{12}\end{bmatrix}\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\tag{3}\]
のようにまとめて表せます。ここで行列 $W$ とベクトル $\boldsymbol{u}$ および $\boldsymbol{x}$ を
\[W=\begin{bmatrix}w_{00} & w_{01} & w_{02}\\ w_{10} & w_{11} & w_{12}\end{bmatrix},\quad
\boldsymbol{u}=\begin{bmatrix}u_0\\u_1\end{bmatrix},\quad\boldsymbol{x}=\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\tag{4}\]
によって定義すると、$b$ 層の入力総和は
\[\boldsymbol{u}=W\boldsymbol{x}\tag{5}\]
と表すことができます。これを活性化関数 $f(u)$ に通して、この層のそれぞれのニューロンからの出力値
\[\boldsymbol{y}=f(\boldsymbol{u})=f(W\boldsymbol{x})\tag{6}\]
を得ることができます。このように行列を使うと、各層のニューロンをまとめて1つのユニットとして扱うことができます(実装する際にはニューロンごとにではなく、層ごとに関数を定義します)。
Python で小さなニューラルネットワークを作ってみましょう。
最初にネットワークの層の機能をもつ関数を定義しておきます。
# Neural_Network
# In[1]
import numpy as np
# 恒等関数
def identity(x):
return x
# シグモイド関数
def sigmoid(x):
f = 1 / (1 + np.exp(-x))
return f
# 層関数
def layer(xv, wm, func=identity):
xv = np.append(xv, 1) # 入力信号にダミーを追加
u = np.dot(wm, xv) # 入力総和
return func(u) # 活性化関数に入力総和を渡す
layer()は入力信号 xv と重み行列 wm、関数オブジェクト(活性化関数)func を受け取って、出力値を返します。func にはデフォルトで恒等関数オブジェクト identity が指定されているので、このオプション引数を省略すると、入力総和 u をそのまま出力することになります。また、layer() は自動的にダミー入力を組み込むので、xv にダミー入力を加えた配列を渡す必要はありません。
入力層 2 ユニット、中間層 2 ユニット、出力層 1 ユニットを備えた次のようなモデルを考えます。
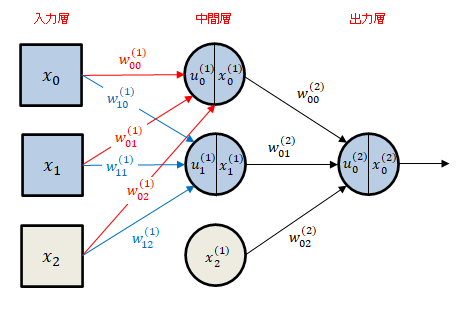
灰色のユニットはダミー信号 $1$ を出力します。中間層と出力層を区別するために、中間層に入る信号の重み、入力総和の肩に $(1)$ を添えます。また、中間層の $k$ 番目のユニットからの出力値を $x_{k}^{(1)}$ と表すことにします。同様に、出力層に入る信号の重み、入力総和の肩に $(2)$ を添え、出力層の $k$ 番目のユニットからの出力値を $x_{k}^{(2)}$ と表します。
中間層の各ユニットに入ってくる入力総和は先ほどと同じく
\[\begin{bmatrix}u_0^{(1)}\\u_1^{(1)}\end{bmatrix}=\begin{bmatrix}w_{00}^{(1)} & w_{01}^{(1)} & w_{02}^{(1)}\\
w_{10}^{(1)} & w_{11}^{(1)} & w_{12}^{(1)}\end{bmatrix}\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\tag{7}\]
と表せます。行列 $W^{(1)}$ とベクトル $\boldsymbol{u}^{(1)}$ および $\boldsymbol{x}$ を
\[W^{1}=\begin{bmatrix}w_{00}^{(1)} & w_{01}^{(1)} & w_{02}^{(1)}\\ w_{10}^{(1)} & w_{11}^{(1)} & w_{12}^{(1)}\end{bmatrix},\quad
\boldsymbol{u}^{(1)}=\begin{bmatrix}u_0^{(1)}\\u_1^{(1)}\end{bmatrix},\quad\boldsymbol{x}=\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\tag{8}\]
によって定義すると、$b$ 層の入力総和は
\[\boldsymbol{u}^{(1)}=W^{(1)}\boldsymbol{x}\tag{9}\]
となります。中間層の各ユニットから出力される値は、
\[\boldsymbol{x}^{(1)}=f(\boldsymbol{u}^{(1)})=f(W^{(1)}\boldsymbol{x})\tag{10}\]
となります。
出力層は 1 ユニットだけなので、中間層から出力層に入ってくる入力総和は
\[u_{0}^{(2)}=w_{00}^{(2)}\ x_{0}^{(1)}+w_{01}^{(2)}\ x_{1}^{(1)}+w_{02}^{(2)}\ x_{2}^{(1)}\tag{11}\]
のようにスカラーとなりますが、これも重みベクトル
\[W^{(2)}=[w_{00}^{(2)}\quad w_{01}^{(2)}\quad w_{02}^{(2)}]\tag{12}\]
と、中間層からの出力ベクトル
\[\boldsymbol{x}^{(1)}=\begin{bmatrix}x_0^{(1)}\\x_1^{(1)}\\x_2^{(1)}\end{bmatrix}\tag{13}\]
の内積
\[u_{0}^{(2)}=W^{(2)}\boldsymbol{x}^{(1)}\tag{14}\]
で表せます。行列形式に合わせて $W^{{2}}$ は行ベクトルで表記しています。出力層から出力される値は、
\[\boldsymbol{x}^{(2)}=f(\boldsymbol{u}^{(2)})=f(W^{(2)}\boldsymbol{x}^{(1)})\tag{15}\]
以上の準備をもとに、適当な入力信号と重み行列を設定して、ネットワークからの出力を確認してみましょう。入力層からの信号にかかる重み行列 $W^{(1)}$、入力層からの信号にかかる重み行列 $W^{(2)}$ をそれぞれ変数 wm1、wm2 に格納します。入力層、中間層、出力層からの信号を、それぞれ変数 xv0、xv1、xv2 に格納します。
適当な入力信号と重み行列を設定して、ネットワークからの出力を確認してみましょう。
# In[2]
# 中間層への入力の重み行列
wm1 = np.array([[1.0, 2.0, 1.5],
[1.5, 1.0, 1.0]])
# 出力層への入力の重み行列
wm2 = np.array([1.0, -0.5, 1.5])
# 中間層への入力信号
xv0 = np.array([1.0, -0.5])
# 出力層への入力信号
xv1 = layer(xv0, wm1, sigmoid)
# ニューラルネットワークからの出力ベクトル
xv2 = layer(xv1, wm2)
xv2 = np.round(xv2, 5)
print("ニューラルネットワークからの出力値 {}".format(xv2))
# ニューラルネットワークからの出力値 1.87718
前回と同じように、$x_0$-$x_1$ 平面上にニューラルネットワークの出力値をプロットしてみましょう。
# In[3]
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 解像度の設定
xn = 33
# x0-x1平面の格子点を作成
xv0_1 = np.linspace(-8.0, 8.0, xn)
xv0_2 = np.linspace(-8.0, 8.0, xn)
X0, X1 = np.meshgrid(xv0_1, xv0_2)
# 中間層への入力の重み
wm1 = np.array([[3.0, 2.0, 2.0],
[2.0, 3.0, -2.0]])
# 出力層への入力の重み
wm2 = np.array([1.0, 1.0, 0.1])
# ニューラルネットワークの出力を格納する変数
Z = np.zeros((xn, xn))
# ニューラルネットワークからの出力
for i in range(xn):
for j in range(xn):
xv0 = np.array([xv0_1[i], xv0_2[j]])
xv1 = layer(xv0, wm1, sigmoid)
Z[j][i] = layer(xv1, wm2)
# 曲面を描画
fig = plt.figure(figsize = (10, 6))
ax = fig.add_subplot(111, projection='3d')
ax.set_xlabel("x0", size=16, labelpad=10)
ax.set_ylabel("x1", size=16, labelpad=10)
ax.set_zlabel("output", size=16)
ax.plot_surface(X0, X1, Z, color="green")
plt.show()
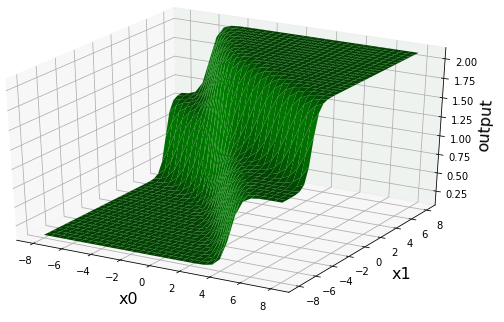
単体ニューロンに比べると複雑な出力分布になっていますね。ニューラルネットワークの中間層を増やしていけば、表現力はさらに向上し、より柔軟なモデルを構築できるようになります。
コメント
下記は誤植と思われますので、ご確認ください。
In[1] プログラムで、def layer(xv, wv, func = identify): → def layer(xv, wm, func = identify):
直しました。
ありがとうございます。m(_ _)m
In[2] プログラムの上の図に入力と出力の線を追加して、
x0, x1,(入力) wm1_00, wm1_01, ,wm1_10, wm1_11, wm2_00, wm2_01, xv0, xv1, xv2,
identity, sigmoid, identity, u0, u1(隠れ層の入力総和)
を自分で書き込んで、プログラムに沿ってlayer( )では入力ベクトルに 1 を追加して、更にそれに対する重み ( wm1_02, wm1_12 あるいは wm2_02 ) も追加して、何とか 4 本の行列を使った式を書き下せました。
申し訳ないです。
In[2] で実装するモデルの説明が不足していました。
詳細な説明文を加筆して、図も差し替えておきました。
【お知らせ】
数式に式番号を付けました。
また、(5) 式の具体的な表式として (3) 式を付け加えました。