この記事では統計分析や機械学習の分野で多用されるガウス関数の定義と性質、正規分布、Python における実装方法、関連するライブラリ等について解説します。
ガウス関数
ガウス関数(Gaussian function)は
\[\varphi(x)=a\exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\}\tag{1}\]
で定義される関数です。ガウシアンとよばれることもあります。$\mu$ は中心の位置、$\sigma$ は関数の広がりを決める定数です。機械学習の分野では近似曲線の線形基底関数としてガウス関数が用いられることがあります。ガウス関数を Python で実装してグラフの形を確認してみましょう。
# NUMPY_GAUSSIAN_FUNCTION
# In[1]
import numpy as np
import matplotlib.pyplot as plt
# ガウス関数を定義
def gauss(x, a=1, mu=0, sigma=1):
return a * np.exp(-(x - mu)**2 / (2*sigma**2))
# Figureを作成
fig = plt.figure(figsize=(8, 6))
# FigureにAxesを追加
ax = fig.add_subplot(111)
# Axesのタイトルを'Gaussian Function'に設定
ax.set_title("Gaussian Function", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸ラベルを設定
ax.set_xlabel("x", fontsize=14)
ax.set_ylabel("y", fontsize=14)
# 軸範囲を設定
ax.set_xlim([-4, 8])
ax.set_ylim([0, 1.2])
# -4~8まで0.1刻みの数値の配列
x = np.arange(-4, 8, 0.1)
# グラフに描く関数
f1 = gauss(x)
f2 = gauss(x, a=0.5, mu=2, sigma=2)
# Axesにガウス関数を描画
ax.plot(x, f1, color="red", label="a=1.0, μ=0, σ=1")
ax.plot(x, f2, color="blue", label="a=0.5, μ=2, σ=2")
# 凡例の表示
ax.legend(fontsize=14)
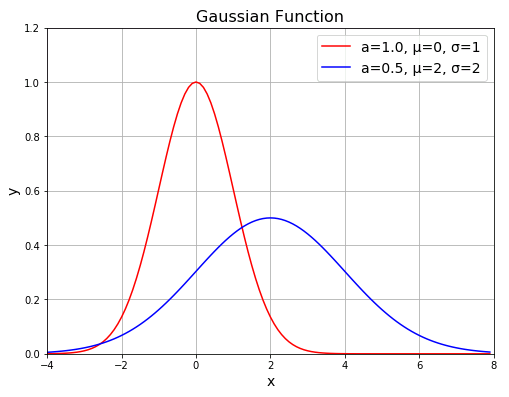
コードの中で定義した gauss() は x のみを必須引数とし、a, mu, sigma はそれぞれ $a,\ \mu,\ \sigma$ に対応するオプション引数となっています。赤いラインは $a=1,\ \mu=0,\ \sigma=1$ としたガウス関数
\[\varphi(x)=\exp\left(-\frac{x^2}{2}\right)\]
のグラフです。青いラインは
\[\varphi(x)=\frac{1}{2}\exp\left\{-\frac{(x-2)^2}{8}\right\}\]
のグラフです。赤いラインと比較すると、ピーク値は半分 ($a=0.5$) になり、中心位置(ピークの位置)は右にずれ ($\mu=2$)、全体の幅は $2$ 倍になっています ($\sigma=2$)。
ガウス積分
ガウス関数 $\exp(-cx^2)\;(c\gt 0)$ の無限区間積分をガウス積分とよび、その積分値が $\sqrt{\pi/c}$ で与えられることが知られています。
\[\int_{-\infty }^{\infty }e^{-cx^2}dx=\sqrt{\frac{\pi}{c}}\tag{2}\]
SymPy をインポートして確認してみましょう。
# SYMPY_GAUSSIAN_INTEGRAL
# In[1]
import sympy
# 記号x,cを定義
x = sympy.Symbol('x')
c = sympy.Symbol('c', positive=True)
# 無限大記号を定義
oo = sympy.oo
# ガウス関数
f = sympy.exp(-c*x**2)
# ガウス積分
g = sympy.integrate(f, (x, -oo, oo))
print(g)
# sqrt(pi)/sqrt(c)
正規分布
式 (1) で表される一般的なガウス関数
\[\varphi(x)=a\exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\}\tag{1}\]
を無限区間で積分してみます。ガウス関数は左右対称形なので、$\mu$ は関数を左右にスライドさせるだけで無限区間積分に寄与しません。すなわち、
\[\varphi(x)=a\exp\left(-\frac{x^2}{2\sigma^2}\right)\tag{3}\]
を考えればよいことになります。
\[c=\frac{1}{2\sigma^2}\tag{4}\]
とおいて式 (3) を積分すると、ガウス積分の公式より
\[a\int_{-\infty }^{\infty }e^{-cx^2}dx=a\sqrt{\frac{\pi}{c}}\tag{5}\]
となります。この積分値が $1$ になるように $a$ を定めると、
\[a=\sqrt{\frac{c}{\pi}}=\frac{1}{\sqrt{2\pi}\sigma}\tag{6}\]
となります。このような形で規格化されたガウス関数
\[N(\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\}\tag{7}\]
のことを正規分布 (normal distribution) とよびます。このとき、$\mu$ は平均値、$\sigma^2$ は分散を表すパラメータとなります。
ガウス関数の重ね合わせ
ガウス関数 は機械学習において基底関数として用いられることがあります。ガウス関数を適切に重ね合わせると、たとえば人間の平均身長や国の人口などの成長曲線を近似することができます。以下のサンプルコードは、中心位置 $\mu$ を少しずつずらしたガウス関数を重ね合わせたグラフを描きます。
# NUMPY_GAUSSIAN_SUPERPOSITION
# In[1]
import numpy as np
import matplotlib.pyplot as plt
# ガウス関数を定義
def gauss(x, a=1, mu=0, sigma=1):
return a * np.exp(-(x - mu)**2 / (2*sigma**2))
# Figureを作成
fig = plt.figure(figsize=(8, 6))
# FigureにAxesを追加
ax = fig.add_subplot(111)
# Axesのタイトルを'Gaussian Function'に設定
ax.set_title("Gaussian Function", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸ラベルを設定
ax.set_xlabel("x", fontsize=14)
ax.set_ylabel("y", fontsize=14)
# 軸範囲を設定
ax.set_xlim([-3, 3])
ax.set_ylim([0, 3])
# -3~3まで0.1刻みの数値の配列
x = np.arange(-3, 3, 0.1)
# 関数fの初期値
f = 0
# 中心位置をずらしながら重ね合わせる
for k in range(5):
g = gauss(x, mu=k)
ax.plot(x, g, label="φ{}".format(k))
f += g
# Axesに重ね合わせたガウス関数を描画
ax.plot(x, f, color="black", label="φ0+φ1+φ2+φ3+φ4")
# 凡例を表示
ax.legend()
# ファイルを保存
plt.savefig("gauss.png", bbox_inches="tight")
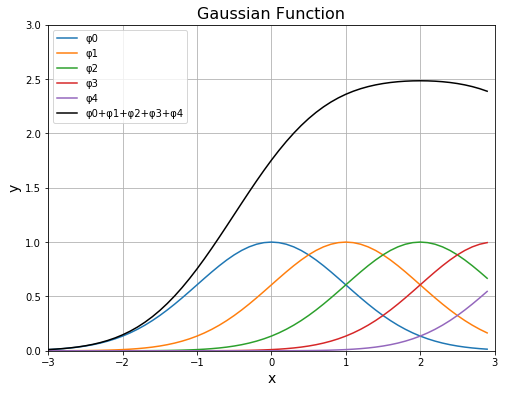
2変数ガウス関数
2変数のガウス関数 は
\[\varphi(\boldsymbol{\mathrm{r}})=a\exp\left\{-\frac{1}{2}(\boldsymbol{\mathrm{r}}-\boldsymbol{\mu})^T\Sigma^{-1}(\boldsymbol{\mathrm{r}}-\boldsymbol{\mu})\right\}\tag{8}\]
で表されます。$\boldsymbol{\mathrm{\mathrm{r}}}$ と $\boldsymbol{\mu}$ はそれぞれ位置ベクトルと平均ベクトルです。
\[\boldsymbol{\mathrm{r}}=\begin{bmatrix}
x\\ y\end{bmatrix},\quad \boldsymbol{\mu}=\begin{bmatrix}\mu_x\\ \mu_y\end{bmatrix}\tag{9}\]
$\Sigma$ は共分散行列とよばれる $2\times 2$ の行列です。
\[\Sigma=\begin{bmatrix}\sigma_1^2 &\sigma_{12}\\\sigma_{12}& \sigma_2^2\end{bmatrix}\tag{10}\]
全区間で積分したときに $1$ になるように規格化すると、
\[a=\frac{1}{2\pi}\frac{1}{\sqrt{\mathrm{det}\Sigma}}\tag{11}\]
となります。$\mathrm{det}\Sigma$ は $\Sigma$ の行列式であり、
\[\mathrm{det}\Sigma=\sigma_{1}^2\sigma_{2}^2-\sigma_{12}^2\tag{12}\]
によって計算されます。規格化された 2 変数ガウス関数
\[\varphi(\boldsymbol{\mathrm{r}})=\frac{1}{2\pi}\frac{1}{\sqrt{\mathrm{det}\Sigma}}\exp\left\{-\frac{1}{2}(\boldsymbol{\mathrm{r}}-\boldsymbol{\mu})^T\Sigma^{-1}(\boldsymbol{\mathrm{r}}-\boldsymbol{\mu})\right\}\tag{13}\]
は 2 変数正規分布の確率密度関数を表しています。2 変数正規分布は scipy.stats の multivariate_normal.pdf() で計算できます。
# SCIPY_MULTIVARIATE_NORMAL_PDF
# In[1]
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.stats import multivariate_normal
# FigureとAxesの設定
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.set_xlim(-6.0, 6.0)
ax.set_ylim(-6.0, 6.0)
ax.set_zlim(0.0, 0.14)
ax.set_xlabel("x", size=16)
ax.set_ylabel("y", size=16)
ax.set_zlabel("z", size=16)
ax.view_init(elev=45, azim=45)
# 格子点を作成
n = 128
x = np.linspace(-6, 6, n)
y = np.linspace(-6, 6, n)
X, Y = np.meshgrid(x, y)
pos = np.dstack((X, Y))
# 2変数ガウス関数
mu = np.array([0.5, 1.0])
sigma = np.array([[1.0, -0.2],[-0.2, 1.0]])
Z = multivariate_normal(mu, sigma).pdf(pos)
# 2変数ガウス関数を3次元プロット
ax.plot_surface(X, Y, Z, cmap="coolwarm",
cstride=1, rstride=1)
plt.show()
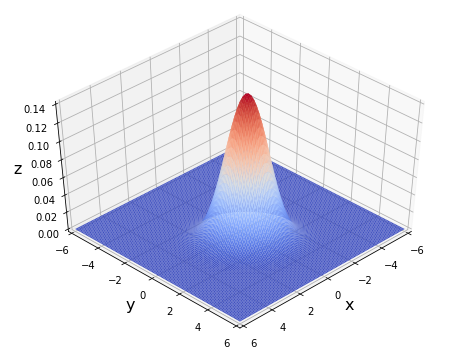
コメント
SCIPY_MULTIVARIATE_NORMAL_PDF プログラムで、2 つの質問がありますのでよろしくお願いいたします。
1. (10) 式の σ_12 は 2 変数の相関を表して同じ値を指定するようですが、プログラムで 0.2 と -0.2 になっているのは誤植でしょうか。
2. pos に X, Y ではなく、np.dstack(X, Y) としなければならないのは何故でしょうか。
1. (10)式は誤植です。申し訳ありません。修正しておきました。m(_ _)m
2. 確率密度関数を得る pdf() メソッドが複数の配列を受け取れないので、np.dstack(X, Y) で一つにまとめて渡しています。
ご回答ありがとうございました。
np.dstack(X, Y) は np.dstack((X, Y)) の誤りでした。
2 変数の pdf の計算には X, Y から作る格子点の座標が必要だが、X, Y という二つの配列をそのまま渡せないので dstack で連結して渡しているということですね。ところでマニュアルでは以下のような説明がありましたが、後半の意味がよくわかりませんでした。
The input quantiles can be any shape of array, as long as the last axis labels the components.
ご教示いただけるとありがたいです。
直訳すると意味がわかりづらくなるので、かなり意訳しますが、「最後の軸でデータが区別できるようになっていれば、どんな形の配列を渡してもいいですよ」という意味です。pdf() には一つの配列しか渡せないので、たとえば二変量確率密度を計算する場合は、どの部分が X に、またどの部分が Y に対応するデータなのか区別する必要があります。それで、このメソッドは「最後の軸、つまりネスト最深部の軸に沿って、データを区分する」というルールを設けています。このような理由で、最後の軸に沿って配列を連結する np.dstack() で結合させたデータを pdf() に渡しています。
ご回答ありがとうございました。私が調べた中で、X, Y を flatten( ) メソッドで 1 次元配列に変換して、さらにnp.stack( axis=1 ) でそれらを連結してから pdf( ) に渡している例があったのですが、それでもOKだった理由がわかりました。
間違えました。(10)式ではなく、SCIPY_MULTIVARIATE_NORMAL_PDF が誤植です。0.2 → -0.2 です。申し訳ないです。