groupby操作による部分的なデータ集約
部分的なデータについての集約は、groupby とよばれる操作によって実現できます。具体例を使って説明するために、重複ラベルを含むデータフレームを作成しておきます。
# PANDAS_GROUPBY_BASIC
# In[1]
import numpy as np
import pandas as pd
# 重複要素を含むデータフレームを作成
df = pd.DataFrame({"key":["A", "B", "A", "A", "B"],
"X":[1, 2, 4, 8, 16],
"Y":[1, 3, 9, 27, 81]})
print(df)
# key X Y
# 0 A 1 1
# 1 B 2 3
# 2 A 4 9
# 3 A 8 27
# 4 B 16 81
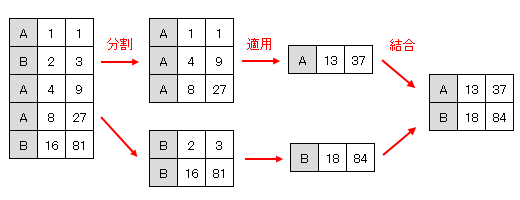
下図にあるように、groupby は分割 (split), 適用 (apply), 結合 (combine) という三段階を踏んで実行されます (下図の例では apply は要素の合計をとる操作です)。
pandas でこのような操作を実行するためには、最初に groupby()メソッドを使って、DataFrameGroupByオブジェクト を生成することから始めます。
# In[2]
# DataFrameGroupByオブジェクトを生成
gb = df.groupby("key")
print(gb)
# <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x05E7FF70>
DataFrameGroupByオブジェクトに対して集約メソッドを適用すると、分割されていたデータセットが再結合されて新しいデータフレームが生成されます。
# In[3] # ラベルXの共通要素ごとに総和を計算 s = gb.sum() print(s) # X Y # key # A 13 37 # B 18 84
GroupBy.aggregate()
GroupBy.aggregate() は複数の集約操作をまとめて実行するメソッドです。agg() という短縮名で使うこともできます。以下のコードを実行すると、共通要素ごとに [最大値、最小値、平均値] をまとめて計算します。
# In[4] # 共通要素ごとに最大値、最小値、平均値を計算 x = gb.agg(["max", "min", "mean"]) print(x) # X Y # max min mean max min mean # key # A 8 1 4.333333 27 1 12.333333 # B 16 2 9.000000 81 3 42.000000
GroupBy.filter()
GroupBy.filter() はグループをフィルタリングするメソッドです。引数には、ある列に集約メソッドを適用した結果についての条件式を渡します。たとえば、列ラベル “X” の要素の最大値が 10 以下となるグループを取得する場合は次のようなコードを記述します (上の図を見てわかるように、要素 “A” に対応するグループがこの条件を満たしています)。
# In[5] # "X"列の最大値が10以下となるグループを取得 f = gb.filter(lambda t: t["X"].max() <= 10) print(f) # key X Y # 0 A 1 1 # 2 A 4 9 # 3 A 8 27
GroupBy.transform()
GroupBy.transform() はグループごとにデータの変換を行なって再結合させます。たとえば、グループごとに (そのグループの) 平均値を引く場合は、以下のようなコードを記述します。
# In[6] # グループごとに平均値を引く t = gb.transform(lambda t: t - t.mean()) print(t) # X Y # 0 -3.333333 -11.333333 # 1 -7.000000 -39.000000 # 2 -0.333333 -3.333333 # 3 3.666667 14.666667 # 4 7.000000 39.000000
groupby操作の実践例
以下のコードを実行すると、ある学校における 2 クラスの英語と数学の試験結果を記載したファイル (me_score.csv) を読み込んでデータフレームに格納します。
# PANDAS_GROUPBY_EXERCISE # In[1] import numpy as np import pandas as pd # ファイルのパス u = "https://python.atelierkobato.com/wp-content/uploads/2019/07/me_score.csv" # CSVファイルを読み込んでデータフレームに変換 me_score = pd.read_csv(u, encoding="SHIFT-JIS", header=0) print(me_score) # クラス 氏名 性別 英語 数学 # 0 1 玉田 悠悟 m 71 60 # 1 1 三芳野 春 m 63 69 # 2 1 水本 大貴 m 76 72 # ・・・・・・・・・ [中略] ・・・・・・・・ # 38 2 曵原 じゅんこ f 74 72 # 39 2 茶畑 加織 f 50 66
m は male (男)、f は female (女) の頭文字です。
データフレームを "クラス" で分割して、DataFrameGroupByオブジェクトを生成してみます。
# In[2]
# SeriesGroupByオブジェクトを生成
gb_c = me_score.groupby("クラス")
print(gb_c)
# <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x05E7F3F0>
gb_c に mean()メソッドを使うと、クラス別の平均点を求めることができます。
# In[3] # クラスごとに数学の平均点を計算 print(gb_c.mean(numeric_only=True)) # 英語 数学 # クラス # 1 66.95 60.30 # 2 58.00 59.85
次はデータセットを "性別" で分割し、"英語" のデータをもつ SeriesGroupByオブジェクトを生成します。
# In[4]
# SeriesGroupByオブジェクトを生成
gb = me_score.groupby("性別")["英語"]
print(gb)
# <pandas.core.groupby.groupby.SeriesGroupBy object at 0x05BEDF30>
mean()メソッドで男女別の平均点を計算できます。
# In[5] # 男女別に英語の平均点を計算 s = gb.mean() print(s) # 性別 # f 61.10 # m 63.85 # Name: 英語, dtype: float64
aggregate() メソッドを使って、クラス別の数学の最高点と最低点を取得してみましょう。
# In[6]
# SeriesGroupByオブジェクトを生成
gb = me_score.groupby("クラス")["数学"]
# クラス別の数学の最高点と最低点を取得
x = gb.agg(["max", "min"])
print(x)
# max min
# クラス
# 1 93 43
# 2 77 36
コメント
下記は誤植と思われますので、ご確認ください。
GroupBy.filter( ) の説明文で、列ラベル”Y” → 列ラベル”X”
GROUPBY_BASIC In[5] プログラムで、< 10 → <= 10
GROUPBY_BASIC In[5] プログラムの実行結果で、列ラベル key と要素を追加。
直しました。
ありがとうございます。m(_ _)m
現在の Google Colab ( python:3.11.11 pandas:2.2.2 ) を利用すると PANDAS_GROUPBY_EXERCISE In[3] のプログラムは、
TypeError: agg function failed [how->mean,dtype->object]
を発生します。min() や max() は OK でした。
いろいろ試してみたのですが、mean() の引数に何か文字リテラルを与えると、うまく動作するようです。
pandas のバージョンが 1.3 以降、データフレームに数値型ではない列(このコードの例では氏名や性別などの列)が含まれていると、引数なしで mean() を適用できなくなったようです。引数に numeric_only=True を渡せば解決するようですが、ご指摘の通り、適当な文字リテラルを入れても動作するようです。