複数モデルの比較
今回は複数の非線形モデルを作成して、曲線の形状や評価値を見ながら、比較検討作業を行ないます。そのための準備として、最初に「任意の関数オブジェクトを渡すと、平均 2 乗誤差を計算する関数を返す関数」を定義しておきます。
# https://python.atelierkobato.com/model-compare/
# 非線形モデル リストM4-B-1
# モジュールをインポート
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 平均2乗誤差関数
def mse_func(func):
def inner(p, x, y):
mse = np.mean((func(p, x) - y)**2)
return mse
return inner
mse_func() は内部で定義した関数を返す 高階関数 です。受け取る関数 func はパラメータベクトル p と入力データベクトル x を引数に受け取る関数であり、戻り値 inner は引数 p と x、そして目標データ y を受け取る関数です。例として、2 次関数を返す test_func() を定義して mse_func() に渡してみましょう。
def test_func(p, x):
fx = p[0] * x**2 + p[1] * x + p[2]
return fx
z = mse_func(test_func)
z = mse_func(test_func) は関数なので、z に引数 p, x, y を渡したときに、平均 2 乗誤差を返します。
p_t = [2, 3, 1] x_t = np.array([7, 3, 5, 2, 1]) y_t = np.array([118, 30, 61, 17, 8]) print(z(p_t, x_t, y_t)) # 8.2
このように、高階関数を定義すると関数に汎用性を持たせることができるようになります。同じように高階関数を使って「任意の関数オブジェクトを渡して K-分割交差検証を実行する関数」を作成しておきます。アルゴリズムは以前の記事に掲載したものとほとんど同じです。
# https://python.atelierkobato.com/model-compare/
# 非線形モデル リストM4-B-2
# K分割交差検証関数
def cross_valid(x, y, K, func, p_init, method):
N = x.shape[0]
K = 4
xd = np.array_split(x, K)
yd = np.array_split(y, K)
p_train = np.zeros(K)
sd_test = 0
for j in range(K - 1):
x_test = xd[j]
x_train = np.delete(x, slice(j * int(N/K), (j + 1) * int(N/K)))
y_test = yd[j]
y_train = np.delete(y, slice(j * int(N/K), (j + 1) * int(N/K)))
z = minimize(mse_func(func), p_init, args = (x,y), method = method)
p_train = z.x
mse_test = mse_func(func)(p_train, x_test, y_test)
sd_test += np.sqrt(mse_test)
sd_mean = np.round(sd_test/K, 3)
return(sd_mean)
引数には入力データ x と目標データ y、分割数 K, モデルとして採用している関数オブジェクト、パラメータベクトル p の初期値、そして最適化手法を渡します (Powell’s method 以外の手法も選択できます)。
今回使用する 3 種類のモデルもまとめて定義しておきます。
# https://python.atelierkobato.com/model-compare/
# 非線形モデル リストM4-B-3
# モデルA
def model_a(p, x):
return p[0] + p[1] * np.exp(-p[2] * x)
# モデルB
def model_b(p, x):
phi_1 = p[1] * np.exp(-p[2] * x)
phi_2 = p[3] * x ** 0.5
return p[0] + phi_1 + phi_2
# モデルC
def model_c(p, x):
phi_1 = p[1] * np.exp(-(x - p[2])**2 / (2 * p[3]**2))
phi_2 = p[4] * x ** 0.4
phi_3 = p[5] * np.log(abs(x) + 0.01) ** 0.5
return p[0] + phi_1 + phi_2 + phi_3
モデル A は指数関数で表された単純な近似関数です。
\[w(x)=a+b\exp(-cx)\]
$b$ が負の値のとき、$x$ が小さいうちは上昇カーブを描きますが、$x$ が大きくなるにしたがって第 2 項は $0$ に近づくので、最終的には $a$ に収束する関数です。この関数をモデル A として、パラメータを最適化してみます。
# https://python.atelierkobato.com/model-compare/
# 非線形モデル リストM4-B-4
# 動作条件 リストM4-B-1,M4-B-2,M4-B-3の実装
# 入力データ
x = np.array([35, 16, 22, 43, 5,
66, 20, 13, 52, 1,
39, 62, 45, 33, 8,
28, 71, 24, 18, 3])
# 目標データ
y = np.array([85.19, 58.93, 64.27, 68.91, 21.27,
68.88, 60.07, 55.18, 88.08, 8.89,
82.31, 81.18, 80.76, 78.98, 37.55,
75.9, 72.39, 69.51, 62.04, 12.47])
# ★★★★★★★★★★
# モデルを選択
model = model_a
model_title = "Model A"
# パラメータベクトルの初期値を設定
p_init = np.ones(10)
# パラメータベクトルを最適化
z = minimize(mse_func(model), p_init, args = (x,y), method = "powell")
p = z.x
# 平均2乗誤差を計算
mse = mse_func(model)
mse = mse(p, x, y)
# 標準偏差を計算
sd = np.round(np.sqrt(mse), 3)
# 4分割検証
cv = cross_valid(x, y, 4, model, p_init, "powell")
# ★★★★★★★★★★
# FigureとAxesを作成
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
# Axesのタイトルを設定
ax.set_title(model_title, fontsize = 16)
# 目盛線を表示
ax.grid()
# テキストボックス書式辞書を作成
boxdic = {"facecolor" : "white", "edgecolor" : "gray",}
# テキストボックスを表示
ax.text(48, 6, "SD = {}\nSD_mean = {}".format(sd, cv),
size = 14, linespacing = 1.5, bbox = boxdic)
# 軸範囲と軸ラベルを設定
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
ax.set_xlabel("Age", fontsize = 14)
ax.set_ylabel("Weight [kg]", fontsize = 14)
# 身長と体重データの散布図をプロット
ax.scatter(x, y, color = "blue")
# 近似曲線をプロット
x2 = np.linspace(0, 70, 100)
y2 = model(p, x2)
ax.plot(x2, y2, color = "red")
plt.show()
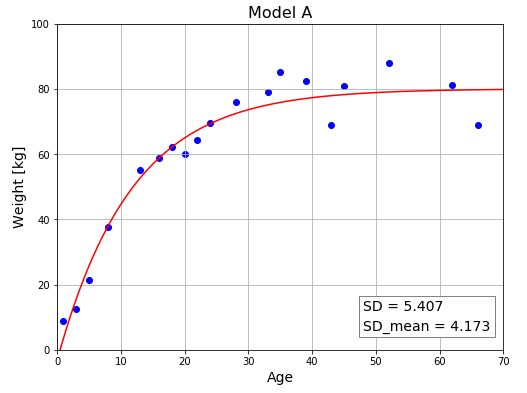
評価値 (4分割検証による標準偏差の平均値) は悪くありませんが、単調増加曲線なので、高齢になると(筋肉量の減少などによって)若干体重が落ちていく傾向を表現することができていません。このモデルでは 70 代以降のデータを上手く予測できない可能性があります。
モデル B はモデル A に基底関数 $\sqrt{x}$ を加えています。
\[w(x)=a+b\exp(-cx)+d\sqrt{x}\]
リストM4-B-4 の「# モデルを選択」というコメント文の下にある model と model_title を次のように書き換えて実行してください。
# モデルを選択 model = model_b model_title = "Model B"
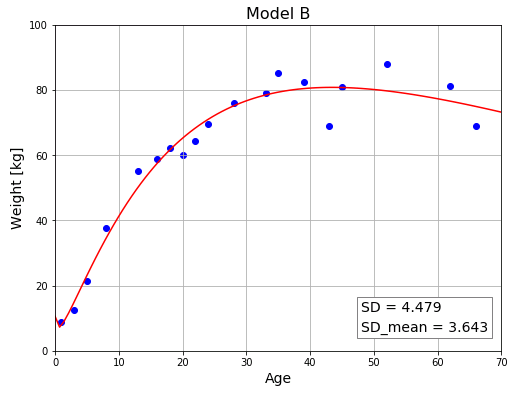
$\sqrt{x}$ の係数 $d$ が負の値をとることによって、曲線全体を下方修正します。高齢になると体重が緩やかに減少するという傾向を表現できています。
モデル C は次式で表されます。
\[a_0+a_1\exp\left\{-\frac{(x-a_2)^2}{2a_3^{2}}\right\}+a_4 x^{0.4}+a_5\log(|x|+0.01)\]
リストM4-B-4 の「# モデルを選択」というコメントの下にある model と model_title を次のように書き換えて実行してください。
# モデルを選択 model = model_c model_title = "Model C"
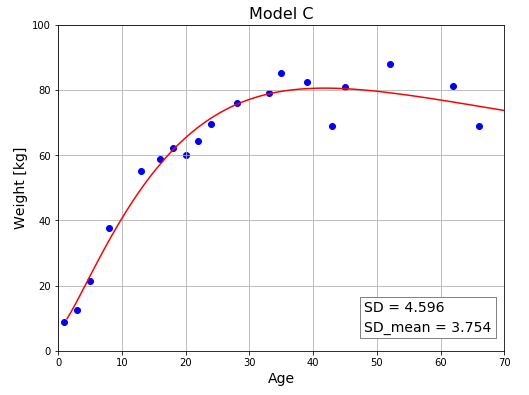
交差検証の評価値はモデル B のほうが少しだけ良さそうです。いずれにしても、(特に 80 代以降の)データ数が少ない段階では、どちらのモデルが優れているかを断定することはできません。機械学習では新しいデータが追加されると、直ちにパラメータを調整するからです。データが増えると、この程度の差であれば、評価値が逆転する可能性 は十分にありえます。
新しいデータを使って評価する
そこで新たに 20 個のデータを入手したと仮定して、モデル B とモデル C の優劣を判定することにします。入力データと目標データを次のように書き換えて比較してみます(表示範囲なども若干修正しておきます)。
# 入力データベクトル
x = np.array([35, 16, 22, 43, 5,
66, 20, 13, 52, 1,
39, 62, 45, 33, 8,
28, 71, 24, 18, 3,
29, 37, 75, 56, 74,
51, 65, 29, 91, 54,
61, 52, 5, 64, 76,
63, 17, 78, 58, 12])
# 目標データベクトル
y = np.array([85.19, 58.93, 64.27, 68.91, 21.27,
68.88, 60.07, 55.18, 88.08, 8.89,
82.31, 81.18, 80.76, 78.98, 37.55,
75.9, 72.39, 69.51, 62.04, 12.47,
62.85, 85.5, 52.29, 46.71, 57.17,
74.54, 51.68, 40.45, 60.02, 75.28,
64.15, 60.56, 19.75, 55.13, 59.77,
63.95, 63.16, 56.37, 58.91, 42.09])
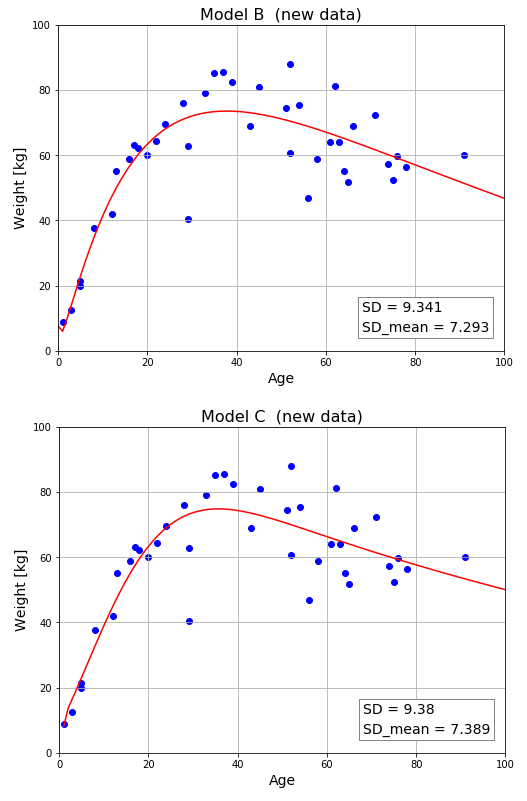
やはり、モデル B のほうが僅かに勝っているようなので、最終的にモデル B を採用します。もちろん 100 % 確実とは言えませんが、実務では、とにかく手持ちのデータを全部放り込んで評価値を出して、暫定的に判断することになります。もちろん、おかしなデータが紛れ込まないように前処理はしておく必要がありますが、それについては pandas の記事などで解説する予定です。
[補足] 記事では皆さんがコピーしやすいように、毎回コードの中にデータを羅列していますが、一般には、この種のデータは ZIP 形式ファイルなどに保存しておいて、必要なときに呼び出すようにします。
コメント