【機械学習】平均二乗誤差
次のように $N$ 人の年齢 $x_k$ と体重 $y_k$ のデータセットが用意されたとします。
\[\boldsymbol{x}=\begin{bmatrix}x_0\\x_1\\\vdots\\x_{N-1}\end{bmatrix}
,\quad\boldsymbol{y}=\begin{bmatrix}y_0\\y_1\\\vdots\\y_{N-1}\end{bmatrix}\tag{1}\]
ベクトル $\boldsymbol{x}$, $\boldsymbol{y}$ をそれぞれ入力データ、目標データとよびます。
ベクトルの各成分 $x_k$, $y_k$ をそれぞれ入力変数、目標変数とよびます。データに存在しない年齢 $x$ が与えられたときに、体重 $y$ を予測できるような関係式を見つけることが 線形回帰の目的です。
平均二乗誤差の定義
20人の年齢と体重のサンプルデータを用意しました。
ただし、25歳以下という年齢制限を設けてあります。
Matplotlib を使って、横軸に年齢、縦軸に体重をプロットしてみます。
# Mean_Squared_Error
# In[1]
# モジュールのインポート
import numpy as np
import matplotlib.pyplot as plt
# 20人の年齢と体重のデータセット
# 年齢は25歳以下に限定
x = np.array([9, 21, 6, 18, 5,
6, 7, 12, 10, 20,
17, 3, 24, 9, 18,
23, 12, 13, 16, 13])
y = np.array([29.01, 78.1, 18.78, 57.94, 14.81,
22.34, 26.31, 41.69, 35.25, 60.92,
69.08, 16, 66.39, 27.06, 68.03,
61.45, 42.07, 40.64, 59.62, 32.22])
# Figureを作成
fig = plt.figure(figsize=(8, 6))
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
# Axesのタイトルを設定
ax.set_title("Age vs. Weight", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸範囲を設定
ax.set_xlim([0, 25])
ax.set_ylim([0, 90])
# 軸ラベルを設定
ax.set_xlabel("Age", fontsize=14)
ax.set_ylabel("Weight [kg]", fontsize=14)
# 身長と体重データの散布図
ax.scatter(x, y, color="blue")
plt.show()
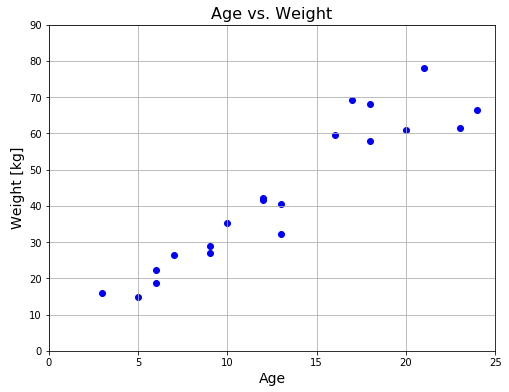
痩せすぎの人がいる一方で肥満体質の人もいるのでバラつきはありますが、全体として年齢が大きいほど体重が重くなるという傾向が見てとれます。そこで「年齢と体重は比例関係にある」と考えて、「このデータを直線で近似しよう」というのが線形回帰モデルの考え方です。上のグラフを見れば点が直線上に乗らないことは一目瞭然なので、かなり強引な手法に思えますが、ともかくも年齢 $x$ と体重 $w(x)$ の間には
\[w(x)=ax+b\tag{2}\]
の関係があると仮定して、実際の年齢データ $x_k$ をこの仮想的な関係式の変数 $x$ に代入します。
\[w(x_k)=ax_k+b\tag{3}\]
$w(x_k)$ と実際の体重データ $y_k$ の差は
\[w(x_k)-y_k=ax_k+b-y_k\tag{4}\]
となります。この差分の2乗を人数分足し合わせて $N$ で割った値
\[Q(a,b)=\frac{1}{N}\sum_{k=0}^{N-1}\{w(x_k)-y_k\}^2=\frac{1}{N}\sum_{k=0}^{N-1}(ax_k+b-y_k)^2\tag{5}\]
を定義します。$Q$ は 平均二乗誤差 (MSE;Mean Square Error) とよばれる量で、この $Q$ を最小とするようなパラメータ $a,\ b$ を 最急降下法 によって見つけます。
平均二乗誤差の可視化
最急降下法 は極小値を探すアルゴリズムなので、複数の極小値をもつような関数については、それなりに工夫が必要となります。そこでまず、$Q$ がどのような形の曲面であるかを Matplotlib で事前に調べておきます。
# In[2]
from mpl_toolkits.mplot3d import axes3d
# 平均2乗誤差MSE
def mse(x, y, a, b):
return np.mean((a * x + b - y)**2)
# Figureを追加
fig = plt.figure(figsize=(10, 6))
# 3DAxeSを追加
ax = fig.add_subplot(111, projection="3d")
# Axesのタイトルを設定
ax.set_title("Mean Square Error", fontsize=16,
position=(0.5, 1.1))
# 軸ラベルを設定
ax.set_xlabel("a", size=14)
ax.set_ylabel("b", size=14)
ax.set_zlabel("Q", size=14)
# 解像度(resolution)を設定
res = 100
# 格子点の作成
a = np.linspace(-15, 15, res)
b = np.linspace(-15, 15, res)
A, B = np.meshgrid(a, b)
# すべての要素が0のres×resサイズの配列
Q = np.zeros((len(a), len(b)))
# 配列Qに格子点の値を格納
for j in range(res):
for k in range(res):
Q[j, k] = mse(x, y, a[j], b[k])
# 視点の設定
ax.view_init(45, 45)
# 曲面を描画
ax.plot_surface(A, B, Q, cmap="viridis")
plt.show()
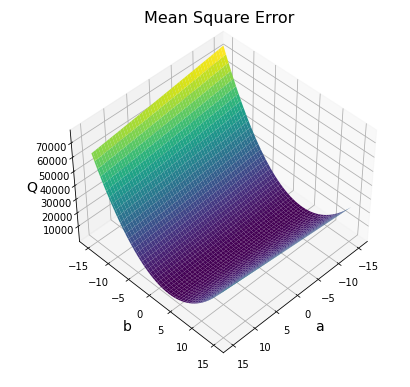
表示されたグラフを見ると、$Q(a,b)$ は谷のような形をしていて、明らかに極小値は1つしかないことがわかります。
平均二乗誤差を最小にするパラメータ
平均二乗誤差 $Q(a,b)$ の定義式を再掲します。
\[Q(a,b)=\frac{1}{N}\sum_{k=0}^{N-1}\{w(x_k)-y_k\}^2=\frac{1}{N}\sum_{k=0}^{N-1}(ax_k+b-y_k)^2\tag{6}\]
目的は最急降下法を使って $Q$ を最小にするような $a,\ b$ を決定することです。
あるステップ数 $t$ におけるパラメータ $a,\ b$ を、それぞれ $a(t),\ b(t)$ と表すことにして、パラメータベクトルを
\[\boldsymbol{p}(t)=\begin{bmatrix}a(t)\\b(t)\end{bmatrix}\tag{7}\]
と定義すると、ステップ数 $t+1$ におけるパラメータベクトルは
\[\boldsymbol{p}(t+1)=\boldsymbol{p}(t)-\alpha\nabla Q|_{\boldsymbol{p}(t)}\tag{8}\]
と表すことができます ($\alpha$ は学習率で正の係数です)。$\nabla Q$ は
\[\nabla Q=\begin{bmatrix}\cfrac{\partial Q}{\partial a}\\\cfrac{\partial Q}{\partial b}\\\end{bmatrix}\tag{9}\]
で表される $Q$ の勾配 (gradient) です。ステップ $t+1$ におけるパラメータベクトルを成分で表すと、
\[\begin{bmatrix}a(t+1)\\b(t+1)\end{bmatrix}=\begin{bmatrix}a(t)-\alpha\left.\cfrac{\partial Q}{\partial a}\right|_{a(t),b(t)}\\
b(t)-\alpha\left.\cfrac{\partial Q}{\partial b}\right|_{a(t),b(t)}\\\end{bmatrix}\tag{10}\]
となります。$Q$ を $a$ と $b$ で偏微分すると
\[\begin{align*}&\frac{\partial Q}{\partial a}=\frac{2}{N}\sum_{k=0}^{N-1}(ax_k+b-y_k)x_k\tag{11}\\[6pt]
&\frac{\partial Q}{\partial b}=\frac{2}{N}\sum_{k=0}^{N-1}(ax_k+b-y_k)\tag{12}\end{align*}\]
となるので、
\[\begin{bmatrix}a(t+1)\\b(t+1)\end{bmatrix}=\begin{bmatrix}a(t)-\cfrac{2}{N}\displaystyle\sum_{k=0}^{N-1}(ax_k+b-y_k)x_k\\b(t)-\cfrac{2}{N}\displaystyle\sum_{k=0}^{N-1}(ax_k+b-y_k)\end{bmatrix}\tag{13}\]
と表されることになります。
# In[3]
# MSEの勾配
def dmse(x, y, a, b):
d_a = 2 * np.mean((a * x + b - y) * x)
d_b = 2 * np.mean(a * x + b - y)
return np.array([d_a, d_b])
# 初期値の設定
a_init, b_init = (-20, 0)
# a,bに初期値を代入
a, b = (a_init, b_init)
# 学習率α
alpha = 0.001
# 収束判定条件
eps = 0.01
# 繰返し最大数
k_max = 100000
for k in range(1, k_max):
a -= alpha * dmse(x, y, a, b)[0]
b -= alpha * dmse(x, y, a, b)[1]
# 勾配の大きさの計算
d = np.sqrt(dmse(x, y, a, b)[0]**2 + dmse(x, y, a, b)[1]**2)
# 勾配の大きさがeps以下になったらループ終了
if d < eps:
break
# 平均2乗誤差を計算
m = mse(x, y, a, b)
# 数値を丸める
a = np.round(a, 5)
b = np.round(b, 5)
d = np.round(d, 6)
m = np.round(m, 3)
print("パラメータベクトル (a, b) = ({0}, {1})".format(a, b))
print("勾配の大きさ d = {}".format(d))
print("平均2乗誤差 mse = {}".format(m))
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111)
# タイトルを設定
ax.set_title("Age vs. Weight", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸範囲を設定
ax.set_xlim([0, 25])
ax.set_ylim([0, 90])
# 軸ラベルを設定
ax.set_xlabel("Age", fontsize=14)
ax.set_ylabel("Weight [kg]", fontsize=14)
# 身長と体重データの散布図
ax.scatter(x, y, color="blue")
# 近似直線をプロット
x2 = np.linspace(0, 25, 100)
y2 = a * x2 + b
ax.plot(x2, y2, color = "red")
plt.show()
# パラメータベクトル (a, b) = (3.01098, 3.93668)
# 勾配の大きさ d = 0.009997
# 平均2乗誤差 mse = 45.194
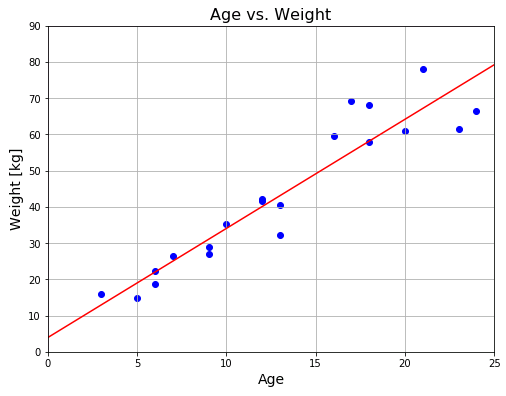
学習率を小さくしているので、環境によっては計算に少し時間がかかるかもしれません。eps 判定で終了していることを確認するために最終地点における勾配の大きさ d を表示させています。繰返し最大数は適当な時間で処理を終了させるための安全弁に過ぎません。勾配の大きさがある程度小さくなっていないと、窪みの底に落ちていないので注意してください。
赤いラインが近似直線です。平均二乗誤差は 45 なので、近似直線と各点との距離の平均は $\sqrt{45}=6.7$ ぐらいになっています。
≫【次の記事】線形回帰モデル② 最小二乗法による単回帰分析
コメント
下記は誤植と思われますので、ご確認ください。
(7) 式の右辺のベクトルの ( ) → [ ]
(10) 式の左辺のベクトルの ( ) → [ ]
(13) 式の右辺の w(x_k)-y_k → ax_k+b-y_k
(8) 式の後ろに (αは学習率、正の係数) を追加したほうがわかりやすいと思いました。
(13)式はひどい誤植でしたね。申し訳ないです。(_ _*)
(8)式もαが何の説明もなく登場してました … わかりにくいですよね。
全部直しておきました。
いつも丁寧に見てくださって、本当にありがとうございます。m(_ _)m
In[3] プログラムの実行結果では、(a, b) = (3.01098, 3.93668) が得られていますが、
In[2] プログラムの実行結果の図からは、MSEが最小になるのは b の値が40~60
の辺りのように見えます。この違いは何が原因なのでしょうか。
申し訳ないです。解像度res=100に比べて、パラメータa,bの範囲が大きすぎたのが原因だと思います。コードを修正して画像も差し替えました。勾配がわかりやすいように、カラーマップを指定しておきました。
a と b をそれぞれ自由に変化させたのがまずかったのだと思います。a * x + b の直線は (ux, uy) を通るという制限をかければ、たとえば a をパラメータとして平均二乗誤差を求めると 2 次曲線を描くグラフが得られました。
ux: x の平均値 uy: y の平均値
# 平均2乗誤差MSE
def mse(x, y, a):
ux=np.mean(x)
uy=np.mean(y)
return np.mean((a * (x – ux) + uy – y)**2)
平均二乗誤差は予測値 p_i から実測値 y_i を差し引いて 2 乗した値の総和
Σ_i (p_i – y_i)^2
を全体数 N で割った値として定義されています。
MSE = Σ_i (p_i – y_i)^2 / N
単回帰分析は、予測値を
p_i = ax_i + b
の形で表します。このとき、パラメータ a, b は互いに完全に独立であり、原理的にはあらゆる a, b の組み合わせから MSE を最小にする a, b を見つけ出す必要があります。もちろん、数値計算では厳密には求められませんが、可能な限り厳密解に近い値を探します。
下記の設定で平均二乗誤差 Q が (a, b) = (3, 4) 付近で最小値を取りそうなのが、何とかわかりました。
# 解像度(resolution)を設定
res = 50
# 格子点の作成
a = np.linspace(2, 4, res)
b = np.linspace(0, 10, res)
A, B = np.meshgrid(a, b)
# 視点の設定
ax.view_init(20, 45)
ありがとうございます。
その設定で試してみました。
確かに最小値がどのあたりにあるか推測できますね。
さらに、下記の設定で a 軸に沿った Q の緩やかなすり鉢状のグラフの底が a=3 付近というのがわかります。
# z軸の設定
ax.set_zlim(0, 100)
# 視点の設定
ax.view_init(0, 90)
実行しました。面白いですね!
確かに特定のパラメータの軸に沿った断面を見れば、どのあたりに極値があるか把握できます。まさに偏微分の考え方ですね。軸の範囲を変えたり、ax.view_init() で視点を変えたりすると、有用な情報が得られますね。最急降下法で得る結果が妥当な値であるか判定するためにも、その前にグラフを分析しておくことが大切だと改めに認識しました。ありがとうございます。m(_ _)m
下記は誤植と思われますので、ご確認ください。
In[3] プログラムのコメントで、# x, y に初期値を代入 → # a, b に初期値を代入
ありがとうございます。
In[3]のコメントを修正しておきました。