北海道室蘭市の降雪現象の分類
2017年11月1日から2018年1月31日にかけての、北海道室蘭市の最低気温 $\boldsymbol{\mathrm{X}}$ と平均湿度 $\boldsymbol{\mathrm{Y}}$ , および「降雪現象なし」を表す $\boldsymbol{\mathrm{T}}$ のデータを用意しました(気象庁提供)。「降雪現象なし」は、「降雪があった場合」を 0, 「降雪がなかった場合」を 1 で表します。言い換えると、雨の中に少しでも雪が混じっていれば 0, 1日中雨だったら 1 となります。
# Snowfall
# In[1]
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d
from scipy.optimize import minimize
# 2017年11月1日~2018年1月31日
# 北海道室蘭市における気象観測データ
# 最低気温[℃]
X = np.array([-10.1, -9.9, -7.8, -7.4, -6.9, -6.8, -6.5, -6.4, -5.5,
-5.4, -5.2, -5.0, -4.9, -4.9, -4.7, -4.7, -4.5, -4.5,
-4.3, -4.3, -4.3, -4.1, -4.1, -4.1, -4.0, -3.8, -3.8,
-3.6, -3.5, -3.4, -3.4, -3.3, -3.2, -3.1, -3.1, -3.0,
-3.0, -2.9, -2.9, -2.9, -2.6, -2.5, -2.4, -2.3, -2.3,
-2.2, -2.1, -2.1, -2.1, -2.0, -1.8, -1.6, -1.6, -1.5,
-1.5, -1.4, -1.3, -1.0, -0.8, -0.4, -0.3, -0.2, -0.2,
-0.1, 0.0, 0.3, 0.6, 0.7, 0.7, 0.7, 0.9, 1.0,
1.1, 1.3, 1.7, 2.0, 2.5, 2.8, 3.6, 3.9, 4.0,
4.1, 4.3, 4.4, 4.7, 7.4, 7.9, 9.7, 9.8, 11.1])
# 平均湿度[%]
Y = np.array([74, 67, 60, 63, 65, 61, 72, 70, 73,
74, 69, 74, 67, 81, 72, 68, 74, 66,
73, 70, 71, 65, 58, 71, 76, 66, 81,
67, 85, 62, 70, 67, 70, 69, 75, 74,
71, 79, 79, 69, 68, 77, 75, 79, 68,
72, 72, 72, 75, 58, 83, 64, 73, 74,
68, 67, 78, 67, 69, 79, 84, 67, 72,
69, 77, 78, 69, 69, 74, 66, 73, 74,
82, 61, 74, 70, 71, 81, 89, 69, 63,
63, 63, 77, 58, 72, 87, 83, 80, 75])
Y2 = Y / 100
# 降雪現象なし
T = np.array([0, 0, 1, 1, 0, 1, 1, 0, 1,
0, 0, 0, 1, 0, 0, 1, 0, 1,
0, 0, 1, 0, 1, 1, 0, 1, 1,
1, 0, 1, 1, 1, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0, 0,
1, 0, 1, 0, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 0, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1])
Y を 100 で割ったデータ Y2 は、scipy.optimize() でパラメータサーチを実行するときに使用するものです(百分率で入力すると少し厄介な問題が生じるので普通の比率に直してあります)。今回は気温と湿度の 2 種類のデータを入力して「降雪現象あり」と「降雪現象なし」に分類することを試みます。実際の観測データがどのような分布になっているかを Matplotlib を使って図示してみましょう。
# In[2]
# 降雪現象が観測された日の最低気温と平均湿度
X_0 = X[T == 0]
Y_0 = Y[T == 0]
# 降雪現象が観測されなかった日の最低気温と平均湿度
X_1 = X[T == 1]
Y_1 = Y[T == 1]
# FigureとAxesの設定
fig, ax = plt.subplots(figsize=(8, 5))
ax.grid()
ax.set_xlim(-10, 10)
ax.set_ylim(50, 90)
ax.set_xlabel("Temperature [${}^\circ$C]", fontsize=14)
ax.set_ylabel("Daily mean humidity [%]", fontsize=14)
# 降雪現象が観測された日のデータを青色で表示
ax.scatter(X_0, Y_0, color="blue", s=16, label="snow", zorder=2)
# 降雪現象が観測されなかった日のデータを赤色で表示
ax.scatter(X_1, Y_1, color="red", s=16, label="rain", zorder=2)
ax.legend()
plt.show()
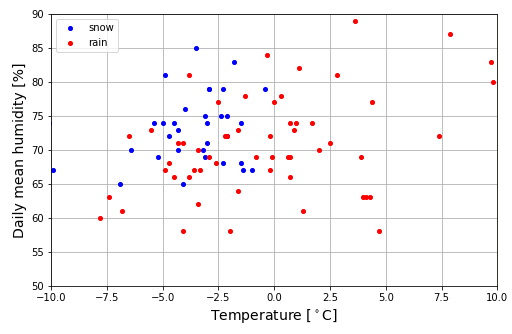
お互いのクラスが入り混じった分布になっていてわかりにくいのですが、なんとなく次のようなラインで分類できそうな気がします。
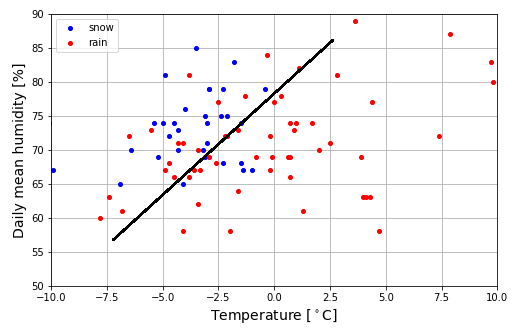
これは、あくまで直感で適当に引いた線です。
平均交差エントロピー誤差関数
前回と同じようにロジスティック回帰によって分類を試みますが、今回は入力データが 2 変数となっています。気温 $x$ と湿度 $y$ が与えられたときに「降雪現象なし」$(t=1)$ となる確率 $P(t=1|x,y)$ を 2 変数ロジスティック関数
\[P(t=1|x,y)=L(x,y)=\frac{1}{1+\exp\{-(ax+by+c)\}}\]
で表すことにして、パラメータベクトル $\boldsymbol{q}=(a,\ b,\ c)$ を最適化するために、平均交差エントロピー誤差
\[E(\boldsymbol{q})=\frac{1}{N}\sum_{k=0}^{N-1}\{-t_k\log L_k-(1-t_k)\log (1-L_k)\}\]
の最小値を求めます。こちらの記事 と同じように計算すると、$E$ の勾配 (gradient) は
\[\nabla E(\boldsymbol{q})=\begin{bmatrix}\cfrac{\partial E}{\partial a}\\
\cfrac{\partial E}{\partial b}\\
\cfrac{\partial E}{\partial c}\end{bmatrix}=\frac{1}{N}\begin{bmatrix}\displaystyle\sum_{k=0}^{N-1}(L_k-t_k)x_k\\
\displaystyle\sum_{k=0}^{N-1}(L_k-t_k)y_k\\\displaystyle\sum_{k=0}^{N-1}(L_k-t_k)\end{bmatrix}\]
で与えられることがわかります。
関数の実装
2 変数ロジスティック関数とその勾配、平均交差エントロピー誤差関数を実装しておきます。
# In[3]
# 2変数ロジスティック関数
def logistic_2(x, y, q):
f = 1 / (1 + np.exp(-(q[0] * x + q[1] * y + q[2])))
return f
# 平均交差エントロピー誤差関数
def cee_logistic_2(q, x, y, t):
f = logistic_2(x, y, q)
c = - np.sum((t * np.log(f) + (1 - t) * np.log(1 - f)))
return c / len(x)
# 平均交差エントロピー誤差関数の勾配
def grad_cee_logistic_2(q, x, y, t):
f = logistic_2(x, y, q)
grad = np.zeros(3)
grad[0] = np.sum((f - t) * x)
grad[1] = np.sum((f - t) * y)
grad[2] = np.sum(f - t)
return grad / len(x)
scipy.minimize() を使ってパラメータを最適化します。
# In[4]
# パラメータの初期値
q0 = [2, -5, 5]
# 平均交差エントロピー誤差関数が最小値をとるパラメータを探索
fit = minimize(cee_logistic_2, q0, args=(X, Y2, T),
jac=grad_cee_logistic_2, method="CG")
# パラメータを取得
q = fit.x
print("(a, b, c):({0:.3f}, {1:.3f}, {2:.3f})".format(q[0], q[1], q[2]))
# (a, b, c):(0.467, -15.486, 12.765)
mpl_toolkits.mplot3d を使って、2変数ロジスティック関数を 3D 表示してみましょう。
# In[5]
# 格子点生成関数を定義
def mesh_2d(xr, yr, n):
x = np.linspace(xr[0], xr[1], n)
y = np.linspace(yr[0], yr[1], n)
X, Y = np.meshgrid(x, y)
return X, Y
# FigureとAxes
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111, projection="3d")
ax.set_title("Logistic function of 2 Variables", fontsize = 16,
position = (0.5, 1.1))
ax.set_xlabel("x", size=15)
ax.set_ylabel("y", size=15)
ax.set_zlabel("P (t=1)", size=15)
ax.set_zlim([0, 1])
# 格子点を作成
XX, YY = mesh_2d([-10, 10], [0.5, 1.0], 129)
# 高度を計算
TT = logistic_2(XX, YY, q)
# 視点の設定
ax.view_init(45, 45)
# 曲面を描画
ax.plot_surface(XX, YY, TT, color="green")
plt.show()
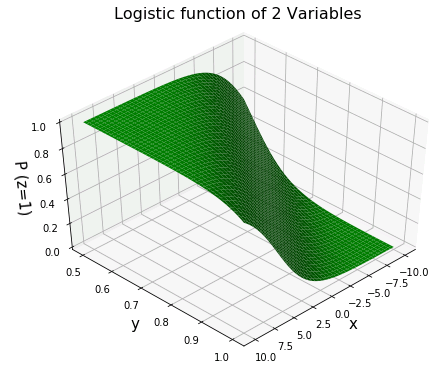
等高線を描いてみると、ロジスティック関数が帯状に変化する様子がよくわかります。
# In[6]
fig = plt.figure(figsize=(4, 4))
ax = fig.add_subplot(111)
ax.set_title("Logistic function of 2 Variables", fontsize=12)
ax.set_xlabel("x", size=12)
ax.set_ylabel("y", size=12)
# ロジスティック関数の等高線をプロット
ct = ax.contour(XX, YY, TT, levels=[0.1, 0.3, 0.5, 0.7, 0.9])
# 高度ラベルを添付
ax.clabel(ct, fontsize=12)
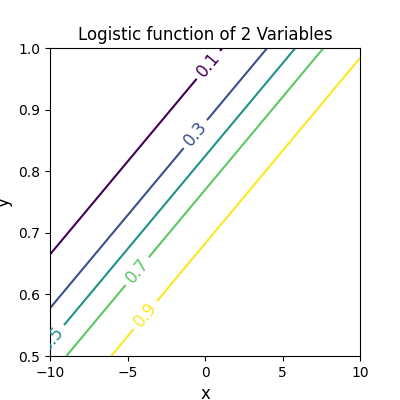
最適化されたロジスティック関数が 0.5 となる $x$ と $y$、すなわち $L(x,y)=0.5$ を表す等高線が決定境界となります。
# In[7]
def mesh_2d(xr, yr, n):
x = np.linspace(xr[0], xr[1], n)
y = np.linspace(yr[0], yr[1], n)
X, Y = np.meshgrid(x, y)
return X, Y
# 等高線描画データ
xr = [-10, 10]
yr = [0.5, 1.0]
n = 257
XX, YY = mesh_2d(xr, yr, n)
TT = logistic_2(XX, YY, q)
# Figureと3DAxesの設定
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_xlabel("Temperature [${}^\circ$C]", fontsize=14)
ax.set_ylabel("Daily mean humidity [%]", fontsize=14)
ax.set_xlim([xr[0], xr[1]])
ax.set_ylim([yr[0], yr[1]])
# 等高線をプロット
ct = ax.contour(XX, YY, TT, colors="black", levels=[0.5])
ax.clabel(ct, fmt = "%0.1f", fontsize=10, zorder=1)
# 降雪現象が観測された日の最低気温と平均湿度
X_0 = X[T == 0]
Y_0 = Y2[T == 0]
# 降雪現象が観測されなかった日の最低気温と平均湿度
X_1 = X[T == 1]
Y_1 = Y2[T == 1]
# 降雪現象が観測された日のデータを青色で表示
ax.scatter(X_0, Y_0, color="blue", s=16, label="snow", zorder=2)
# 降雪現象が観測されなかった日のデータを赤色で表示
ax.scatter(X_1, Y_1, color="red", s=16, label="rain", zorder=2)
# y軸の目盛を%表記に変える
ax.set_yticks(np.arange(0.5, 1.01, 0.1), np.arange(50, 110, 10))
ax.legend()
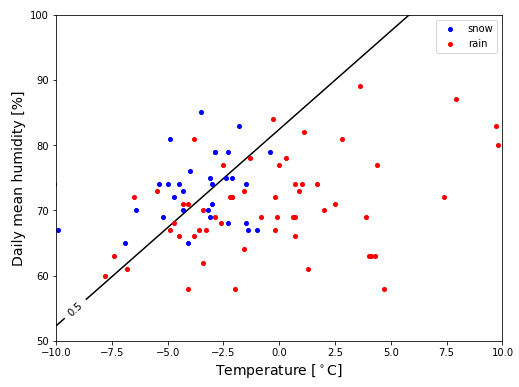
今回の記事で分類の基本問題は終わりです。
次回からいよいよニューラルネットワークについて学びます。
コメント
In[6] プログラムを実行すると下記の Warning が発生します。
UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_yticklabels(np.arange(50, 110, 10))
FixedLocator の使い方がよくわからなかったので、下記のコードに差し替えてとりあえず Warning は出なくなりました。
ax.set_yticks([0.5, 0.6, 0.7, 0.8, 0.9, 1.0], np.arange(50, 110, 10))
私も FixedFormatter や FixedLocator は使ったことがありません。いずれにしても、Warning が発生するコードはよくないので、該当コードを差し替えておきました。
等高線として levels=[0.1, 0.3, 0.5, 0.7, 0.9] のように設定すると平行な 5 本の直線が
描かれるので、2変数ロジスティック関数が帯状に変化するのがよくわかりました。
確かに等高線のほうが変化の様子がわかりやすいですね。記事本文にロジスティック関数の等高線を追加しておきました。ありがとうございます。