【Python統計学】ポアソン分布
この記事の内容(ポアソン分布)は二項分布の知識を前提とするので、簡単に復習しておきます (二項分布の詳細についてはこちらの記事を参照してください)。
$2$ 種類の事象 $A$ と $B$ が、それぞれ確率 $p,\ 1-p$ で起こる試行を $n$ 回繰り返すとき、$A$ が $k$ 回起こる確率は
\[f(k)=P(X=k)={}_{n}\mathrm{C}_{k}\,p^{k}(1-p)^{n-k}\tag{1}\]
で与えられます。この式を使うと、コインを $10$ 枚投げて表が $3$ 枚出る確率などを計算できます。
しかし、$n$ に比べて $p$ が極端に小さな値をとるような(すなわち滅多に起こらないような)事象を扱う場合には少し扱いにくい公式です。
航空機事故の年間発生率
滅多に起こらない事象の代表例として航空機事故があります。国土交通省の運輸安全委員会によると、$2010$ 年から $2019$ 年の $10$ 年間に起きた大型機の事故は $29$ 件でした。$1$ 年間に約 $3$ 件の事故が起きていることになります。
この統計データをもとに、$1$ 年に $k$ 件の航空事故が起きる確率を考えてみましょう。$1$ 日当たりの航空事故発生率は
\[p=\frac{3}{365}\tag{2}\]
です。ただし、同じ日に複数の事故は起こらないと仮定しています。$1$ 年 ($365$ 日) に $k$ 件の交通事故が発生する確率は
\[f(k)={}_{365}\mathrm{C}_{k}\,p^k\,(1-p)^{365-k}\tag{3}\]
で与えられます。scipy.stats.binom() を使って、$1$ 年に $1$ 件の事故が発生する確率を計算してみます。
# POISSON DISTRIBUTION
# In[1]
import numpy as np
from scipy.stats import binom
from scipy.stats import poisson
import matplotlib.pyplot as plt
# 1日あたりの航空機事故発生率
p_day = 3 / 365
# 1年に1件の航空機事故が発生する確率を二項分布で計算する
p1 = binom.pmf(1, 365, p_day)
print("{:.5f}".format(p1))
# 0.14874
このように、現代ではコンピュータを使って二項分布の表式のままで計算できますが、数十年前(1980 年頃)は、コンピュータを使ったとしても $(1-p)^{364}$ のような計算を処理するのは大変でした。まして、ポアソン (Simeon Denis Poisson) が生きていた時代にはコンピュータなど存在しなかったので、$(1-p)^{364}$ などを計算するのは不可能であり、もう少し扱いやすい式が必要でした。
証明は省略しますが、二項分布の確率変数 $X$ の期待値 $\mu=np$ を一定に保ちながら $n\rightarrow \infty$ の極限をとると ($p\rightarrow 0$)、
\[f(k)=\frac{\mu^k}{k!}e^{-\mu}\tag{4}\]
という式になることが知られており、これを ポアソン分布 (Poisson distribution) とよびます。$n$ と $p$ が期待値 $\mu$ に吸収されて表式から消えていることに注目してください。ポアソン分布の形は確率変数の期待値 $\mu$ だけで決まります。
# In[2]
# 確率変数
x = np.arange(0, 11)
# ポアソン分布
y = poisson.pmf(x, 3)
# FigureとAxes
fig = plt.figure()
ax = fig.add_subplot(111)
ax.grid()
ax.set_title("Poisson distribution", fontsize=18, pad=8)
ax.set_xlim(0, 10)
ax.set_ylim(0, 0.25)
ax.set_xlabel("k", fontsize = 15, labelpad=8)
ax.set_ylabel("P(X=k)", fontsize = 15, labelpad=8)
# データをプロット
ax.plot(x, y, marker="o", color="blue")
plt.show()
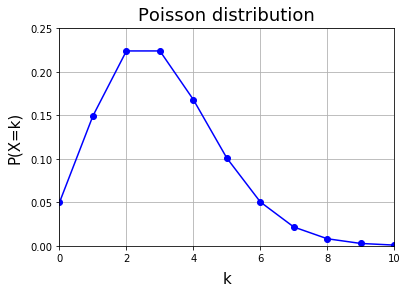
$1$ 年に $2$ 件あるいは $3$ 件の事故が発生する確率が最も高いことがわかります。事故が $0$ 件である確率は $5$ % なので、航空機事故が稀であるとはいえ、全くない年も珍しいことになります。実際、運輸安全委員会のデータによると、1974 年から 2019 年の間に大型機の事故件数が $0$ だった年は 2010 年だけでした。
scipy.stats.poisson.cdf() を使うと累積確率分布を計算できます。たとえば、ある年の大型機の事故が $3$ 件以下である確率 $P(X \leq 3)$ は次のように計算できます。
# In[3]
# ある年の大型機の事故が3件以下となる確率
p_leq3 = poisson.cdf(3, 3)
print("{:.5f}".format(p_leq3))
# 0.64723
$1$ から $P(X \leq 3)$ を引けば、ある年の大型機の事故が $4$ 件以上発生する確率 $P(X \geq 4)$ を計算できます。
# In[4]
# ある年の大型機の事故が4件以上となる確率
p_geq4 = 1 - p_leq3
print("{:.5f}".format(p_geq4))
# 0.35277
二項分布で $np$ 一定のまま極限をとったので、ポアソン分布の期待値も $np$ です。また、二項分布の分散
\[\sigma^2=np(1-p)=\mu\left(1-\frac{\mu}{n}\right)\tag{5}\]
において、$n \rightarrow \infty$ の極限をとると、
\[\sigma^2=\mu\tag{6}\]
となって、分散も期待値に等しいことがわかります。scipy.stats.poisson.var() で期待値 $3$ のポアソン分布にしたがう分散が $3$ になることを確認しておきましょう。
# In[5] # 平均3のポアソン分布の分散 var = poisson.var(3) print(var) # 3.0
参考資料:運輸安全委員会ホームページ
https://jtsb.mlit.go.jp/jtsb/aircraft/air-accident-toukei.php
numpy.random.poisson()
numpy.random.poisson() は、ポアソン分布にしたがう乱数を生成します。
numpy.random.poisson(lam=1.0, size=None)
lam で分布の期待値、size で生成する乱数の個数を指定します。
以下のコードを実行すると、期待値 $\mu=1.5$ のポアソン分布にしたがう乱数を $1000$ 個生成し、各数字の発生比率をヒストグラムで表示します。
# NUMPY_POISSON
import numpy as np
import matplotlib.pyplot as plt
# 疑似乱数ジェネレータのシードを設定
np.random.seed(0)
# μ=1.5のポアソン分布に従う1000個の乱数
k = np.random.poisson(1.5, 1000)
# 階級値の設定
bins = np.arange(0, 10)-0.5
# FigureとAxes
fig = plt.figure()
ax = fig.add_subplot(111)
ax.grid()
ax.set_title("Poisson distribution", fontsize=18, pad=8)
ax.set_ylim(0, 0.4)
ax.set_xlabel("k", fontsize = 15, labelpad=6)
ax.set_ylabel("P(X=k)", fontsize = 15, labelpad=6)
# 乱数の生成比率をプロット
ax.hist(k, bins, rwidth=0.6, density=True, color="darkorange")
plt.show()
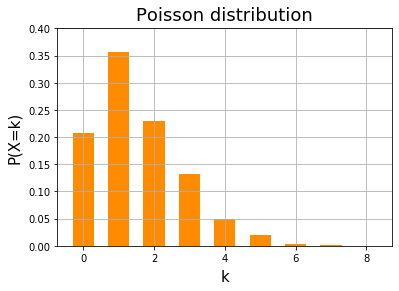
上のコードでは Axes.hist() に density=True で正規化して各乱数の割合をプロットしています。このキーワードを省くか False を指定すれば各乱数の個数をプロットします。
scipy.stats.poisson()
scipy.stats.poisson() はポアソン分布オブジェクトを生成します。
scipy.stats.poisson(*args, **kwds)
オブジェクトに備わるメソッドを使って乱数や確率密度関数、各種統計量を取得できます。たとえば、poisson.rvs() はポアソン分布に従う乱数を生成します。
# SCIPY_POISSON
# In[1]
import numpy as np
from scipy.stats import poisson
import matplotlib.pyplot as plt
# μ=2のポアソン分布に従う乱数を1000個生成
# 乱数ジェネレータのシードを0に設定
k = poisson.rvs(2, size=1000, random_state=0)
# 階級値の設定
bins = np.arange(0, 10)-0.5
# FigureとAxes
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("Poisson distribution", fontsize=18, pad=8)
ax.set_xlabel("k", fontsize = 15, labelpad=6)
ax.set_ylabel("N(k)", fontsize = 15, labelpad=6)
# 各乱数の個数をヒストグラムで表示
ax.hist(k, bins, rwidth=0.6, color="mediumblue")
plt.show()
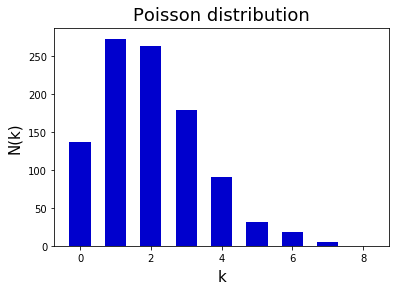
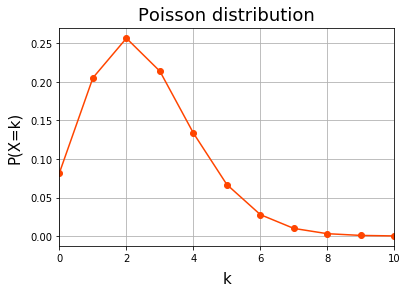
poisson.pmf() はポアソン分布の確率密度関数を返します。
# In[2]
# 確率変数
x = np.arange(0, 11)
# ポアソン分布(μ=2.5)
y = poisson.pmf(x, 2.5)
# FigureとAxes
fig = plt.figure()
ax = fig.add_subplot(111)
ax.grid()
ax.set_title("Poisson distribution", fontsize=18, pad=8)
ax.set_xlim(0, 10)
ax.set_xlabel("k", fontsize = 15, labelpad=8)
ax.set_ylabel("P(X=k)", fontsize = 15, labelpad=8)
# データをプロット
ax.plot(x, y, marker="o", color="orangered")
plt.show()
poisson.cdf(k, mu) は期待値 mu のポアソン分布の累積分布関数、すなわち事象発生回数が k 以下であるような確率分布を返します。
# In[3]
# 確率変数
k = np.arange(0, 11)
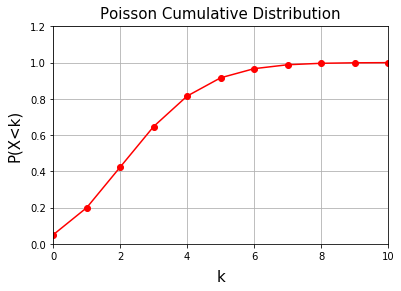
# ポアソン累積分布関数(μ=3)
cdf = poisson.cdf(k, 3)
# FigureとAxes
fig, ax = plt.subplots(1, 1)
ax.grid()
ax.set_title("Poisson Cumulative Distribution", fontsize=15, pad=8)
ax.set_xlim(0, 10)
ax.set_ylim(0, 1.2)
ax.set_xlabel("k", fontsize = 15, labelpad=8)
ax.set_ylabel("P(X<k)", fontsize = 15, labelpad=8)
# データをプロット
ax.plot(k, cdf, marker="o", color="red")
plt.show()
mean(), median(), var(), std() メソッドで、ポアソン分布の期待値、中央値、分散、標準偏差を取得できます。
# In[4]
# ポアソン分布の期待値を設定
mu = 2.5
# 期待値
mean = poisson.mean(mu)
# 中央値
median = poisson.median(mu)
# 分散
var = poisson.var(mu)
# 標準偏差
std = poisson.std(mu)
print("期待値: {:.3f}".format(mean))
print("中央値: {:.3f}".format(median))
print("分散: {:.3f}".format(var))
print("標準偏差: {:.3f}".format(std))
# 期待値: 2.500
# 中央値: 2.000
# 分散: 2.500
# 標準偏差: 1.581
stats() メソッドは期待値、分散、歪度、尖度の $4$ 種の統計量をまとめて取得します。
# In[5]
# μ=2.5のポアソン分布の期待値、分散、尖度、歪度
mean, var, skew, kurt = poisson.stats(mu, moments="mvsk")
print("期待値: {:.3f}".format(mean))
print("分散: {:.3f}".format(var))
print("尖度: {:.3f}".format(skew))
print("歪度: {:.3f}".format(kurt))
# 期待値: 2.500
# 分散: 2.500
# 尖度: 0.632
# 歪度: 0.400
コメント
下記は誤植と思われますので、ご確認ください。
In[3] プログラムで、p_leq3 = 1 – poisson.cdf(3, 3) → p_leq3 = poisson.cdf(3, 3)
In[3] プログラムの実行結果で、0.35277 → 0.64723
In[4] プログラムの実行結果で、0.64723 → 0.35277
式(6) の上の文で、n → 0 → n → ∞
NUMPY_POISSON プログラムの下の文で、プロットでします → プロットします
ありがとうございます。
修正しておきました。m(_ _)m