
ReLU(ランプ関数)
ReLU (Rectified Linear Unit) は、ニューラルネットワークの分野で活性化関数として用いられる関数の1つです。一般には ランプ関数 (ramp function) とよばれ (ramp は「傾斜」の意)、次式で定義されます。
\[R(x)=\begin{cases}0 & (x\lt 0)\\[6pt]x & (x\geq 0)\end{cases}\]
$\mathrm{max}$ 関数を用いると
\[R(x)=\mathrm{max}(x,\ 0)\]
というように簡潔に表現できます。
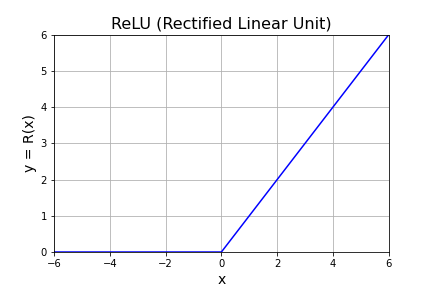
NumPy パッケージを使用する場合、numpy.max() は渡した配列の全要素の中の最大値を返すので、ReLU を実装する場合は numpy.maximum() を使用します。numpy.maximum(x, a) は配列 x の各要素ごとに数値 a と比較して、小さくない方(x の要素と a が等しい場合があるので “大きい方” という表現は不正確)を配列に格納して返します。次のコードで ReLU のグラフを描くことができます。
# PYTHON_RELU
# In[1]
import numpy as np
import matplotlib.pyplot as plt
# Figureを作成
fig = plt.figure(figsize=(6, 4))
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
# Axesのタイトルを設定
ax.set_title("ReLU (Rectified Linear Unit)", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸範囲を設定
ax.set_xlim([-6, 6])
ax.set_ylim([0, 6])
# 軸ラベルを設定
ax.set_xlabel("x", fontsize=14)
ax.set_ylabel("y = R(x)", fontsize=14)
# x,yデータの作成
x = np.linspace(-6, 6, 33)
y = np.maximum(x, 0)
# ReLU(ランプ関数)をプロット
ax.plot(x, y, color="blue")
plt.show()
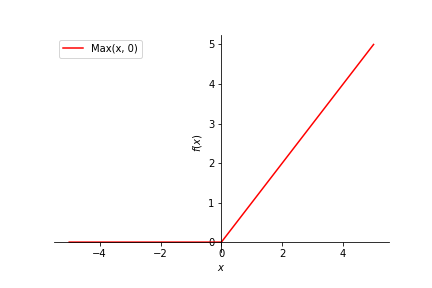
SymPy を使用する場合は sympy.Max()関数で ReLU を定義します。
# SYMPY_RELU
# In[1]
import sympy
# 記号xを定義
sympy.var('x')
# ReLuを定義
r = sympy.Max(x, 0)
# x軸の範囲:[-5, 5], 凡例を表示, 線の色は赤
p = sympy.plot(r, (x, -5, 5), legend=True, line_color='red', label='Max(x,0)')
ReLU関数の微分
定義から明らかなように、ReLU の導関数は ヘヴィサイドの階段関数 となります。
\[\frac{dR(x)}{dx}=H(x)\]
ヘヴィサイドの階段関数を微分するとデルタ関数となるので、ReLU の 2 階導関数はデルタ関数です。
\[\frac{d^2 R(x)}{d x^2}=\delta(x)\]
SymPy にはヘヴィサイドの階段関数 Heviside() と デルタ関数 DiracDelta() が組込まれているので確認することができます。
# RELU_DERIVATIVE
# In[1]
import sympy
# 記号xを定義
sympy.var('x')
# ReLuを定義
r = sympy.Max(x, 0)
drdx1 = sympy.diff(r, x)
drdx2 = sympy.diff(r, x, 2)
print("r'(x) = {}".format(drdx1))
print("r\"(x) = {}".format(drdx2))
# r'(x)=Heviside(x)
# r"(x) = DiracDelta(x)
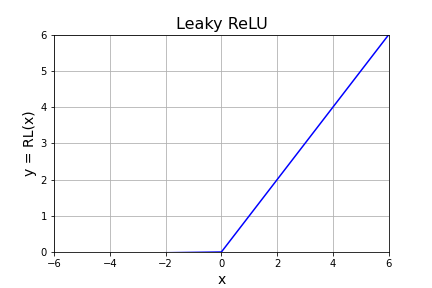
Leaky ReLU
ReLU を改良した Leaky ReLU は次式で定義されます。
\[R_L(x)=\begin{cases}0.01x & (x\leq 0)\\[6pt]x & (x\gt 0)\end{cases}\]
出力が $0$ となって学習が進まないニューロンが出現する dying ReLU という現象を、$x\leq 0$ においても僅かな値をもたせることで防ぎます。NumPy では numpy.where()関数を使って実装することができます。
# LEAKY_RELU
import numpy as np
import matplotlib.pyplot as plt
# Figureを作成
fig = plt.figure(figsize=(6, 4))
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
# Axesのタイトルを設定
ax.set_title("Leaky ReLU", fontsize=16)
# 目盛線を表示
ax.grid()
# 軸範囲を設定
ax.set_xlim([-6, 6])
ax.set_ylim([0, 6])
# 軸ラベルを設定
ax.set_xlabel("x", fontsize=14)
ax.set_ylabel("y = RL(x)", fontsize=14)
# x,yデータの作成
x = np.linspace(-6, 6, 33)
y = np.where(x <= 0, 0.01 * x, x)
# ReLU(ランプ関数)をプロット
ax.plot(x, y, color="blue")
plt.show()
コメント
RELU_01 と 04 の私の実行結果のグラフは、RELU_02 の実行結果とほとんど同じグラフが得られました。記事のグラフは x=0付近で少しゆるい傾斜の直線がはさまっているようです。
RELU_02 の実行結果のグラフの凡例が Max(0, x) になっています。私のPCでも同様でしたが、plot( ) の引数に、label=’Max(x, 0)’ を追加したら直りました。
申し訳ないです。
グラフを差し替えました。
ありがとうございます。m(_ _)m