複数データの同時入力
重みパラメータ $W$ を最適化するためには、たくさんのデータ $\boldsymbol{x}$ を入力し、ネットワークから出力値を得て、実測値との差分から損失関数を計算する必要があります。前回記事 で定義した layer()関数は1度に1個のデータしか渡せなかったので、複数データをまとめて入力 できるように layer() を改良してみましょう。
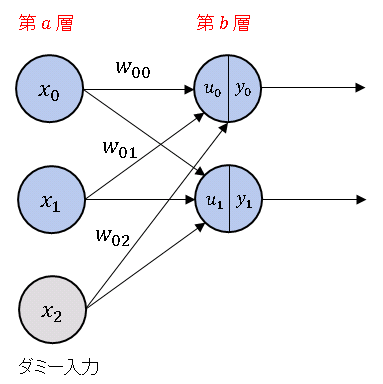
前回記事で扱ったように、上図の $b$ 層への入力総和は
\[\boldsymbol{u}=W \boldsymbol{x}=\begin{bmatrix}w_{00} & w_{01} & w_{02}\\
w_{10} & w_{11} & w_{12}\end{bmatrix}\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\]
で表されます。$x_2$ は常に $1$ の値をとるダミー入力です。行列の演算規則から、$w_{02}$ と $w_{12}$ はバイアスにかかる重みとなります。ネットワークに $3$ 個のデータ
\[\boldsymbol{x_0}=\begin{bmatrix}x_{00}\\x_{10}\\x_{20}\end{bmatrix},\quad
\boldsymbol{x_1}=\begin{bmatrix}x_{01}\\x_{11}\\x_{21}\end{bmatrix},\quad
\boldsymbol{x_2}=\begin{bmatrix}x_{02}\\x_{12}\\x_{22}\end{bmatrix}\]
をまとめて入力することを考えます。$\boldsymbol{x_0},\ \boldsymbol{x_1},\ \boldsymbol{x_2}$ を横に並べた行列
\[X=[\boldsymbol{x_0}\ \boldsymbol{x_1}\ \boldsymbol{x_2}]=\begin{bmatrix}
x_{00} & x_{01} & x_{02}\\ x_{10} & x_{11} & x_{12}\\x_{20} & x_{21} & x_{22}\end{bmatrix}\]
を定義すると、行列演算の性質から、それぞれのデータに対応する入力総和は $U=WX$ で計算することができます(行列はベクトルを並べたもの考えることができます)。
\[U=\begin{bmatrix}u_{00} & u_{01} & u_{02}\\u_{10} & u_{11} & u_{12}\end{bmatrix}
=\begin{bmatrix}w_{00} & w_{01} & w_{02}\\ w_{10} & w_{11} & w_{12}\end{bmatrix}
\begin{bmatrix}x_{00} & x_{01} & x_{02}\\ x_{10} & x_{11} & x_{12}\\x_{20} & x_{21} & x_{22}\end{bmatrix}\]
行列 $U$ の縦に並んだ成分(入力総和ベクトル)は、行列 $X$ の縦に並んだ成分(入力ベクトル)に対応しています(下図参照)。
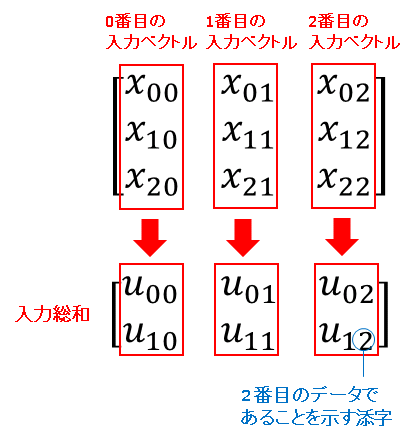
ちなみに当サイトではベクトルや行列の成分を 0 番から数えていますが、これは NumPy の配列インデックスに対応させるためです。
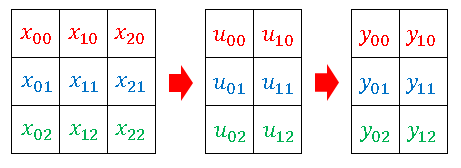
それでは、layer()関数を再定義してみましょう。下図にあるように、2次元配列の中に入力ベクトル (1次元配列) を縦積みして、入力総和ベクトルと出力ベクトルも同じ形式で揃えるようにします。
$U=WX$ を転置すると、
\[U^T=(WX)^T=X^TW^T\]
となるので、実装するときは
\[U^T=\begin{bmatrix}x_{00} & x_{10} & x_{20}\\ x_{01} & x_{11} & x_{21}\\x_{02} & x_{12} & x_{22}\end{bmatrix}
\begin{bmatrix}w_{00} & w_{10}\\ w_{01} & w_{11}\\w_{02} & w_{12}\end{bmatrix}\]
の形でデータを処理します。
# Multi_Input
# In[1]
import numpy as np
# 恒等関数
def identity(x):
return x
# シグモイド関数
def sigmoid(x):
f = 1 / (1 + np.exp(-x))
return f
# ニューラルネットワークの層
def layer(xm, wm, func = identity):
if xm.ndim == 1:
xm = np.append(xm, 1)
else:
dummy = np.ones((xm.shape[0], 1)) # ダミー信号
xm = np.append(xm, dummy, axis=1) # 入力信号にダミー信号を追加
u = np.dot(xm, wm.T) # 入力総和を計算
if u.ndim == 0:
return np.array([[func(u)]])
elif u.ndim == 1:
return np.array([func(u)])
else:
return func(u)
シグモイド関数 を組込んだ層の出力を確認しておきます。
# In[2]
# [.1 .2],[.3 .4],[.5 .6]を同時入力
X = np.array([[.1, .2],
[.3, .4],
[.5, .6]])
# 重み行列を設定
W = np.array([[0.5, -1.0, 1.5],
[2.0, 3.0, -1.5]])
# Xを入力して出力を得る
Y = layer(X, W, sigmoid)
Y = np.round(Y, 3)
print(Y)
# [[0.794 0.332]
# [0.777 0.574]
# [0.76 0.786]]
コメント
とてもわかりやすい記事をありがとうございます。
複数入力のニューラルネットワークの構造がよくわからず躓いていたところで、とても助かりました。
一つ質問させてください。
入力が複数の場合、出力を一つにすることは可能なのでしょうか?
例として二層のニューラルネットワークを考えます。
入力を4つの時系列データ(10,4)、ニューロンの数を20とします。
一層目 重みw1(20,10)*入力x(10,4)→出力y1(20,4)
二層目 重みw2(1,20)*入力y1(20,4)→出力y2(1,4)
となり、入力と出力が同数になってしまいます。
回答いただけると幸いです。
よろしくお願い致します。
ニューラルネットワークは1つのデータに対して、1つの予測値(数値あるいはベクトル)が対応します。ご質問の例であれば、4つのデータを a, b, c, d とした場合、それぞれ個別にネットワークに入力すると、
データ a を入力 ⇒ データ a に対する予測値
データ b を入力 ⇒ データ b に対する予測値
データ c を入力 ⇒ データ c に対する予測値
データ d を入力 ⇒ データ d に対する予測値
のような結果を得るわけですが、a, b, c, d をまとめて入れることで、このような作業を1回で済ませられます。
a, b, c, d を入力 ⇒ a, b, c, d それぞれに対する予測値
したがって、出力数(予測値の数)は入力数と同じく4つとなるはずです。
下記は誤植と思われますので、ご確認ください。
In[1] プログラムの上の文で、X=[x0, x1, x2] → X=[x0 x1 x2]
修正しました。
ありがとうございます。
In[2] プログラムの X に1次元のデータ: X=np.array([.1, .2]) を入力するとエラーが
発生しました。
layer( ) 関数の冒頭で xm.ndim の次元が 1 だった場合のエラー処理も必要だと
思われます。
ご指摘のように、layer()に一次元配列を渡すとエラーになることを確認しました。layer()を修正しておきました。
ありがとうございます。助かりました。m(_ _)m
In[1] プログラムで、「# uが1次元配列なら縦ベクトルに変形」するのは
なぜでしょうか。
次の記事の In[6] 2プログラムの layer( ) 関数では、この処理がありませんでした。
申し訳ないです。出力値の次元を揃えるために書いたつもりでしたが間違っていました。コードを書き直しておきました。
次の記事のIn[6]は2クラス分類マップなので出力値が二次元配列になるのがわかっていて、またこのコードが次回以降に再利用されることもないので、layer()の中身を簡略化してあります。
1 次元の配列を 2 次元の配列にするのであれば、
if u.ndim == 0:
return np.array( [ [ func(u) ] ] )
ではなくて、
if u.ndim == 1:
return np.array( [ func(u) ] )
となると思いますが、ご確認ください。
申し訳ないです。修正前のコードで「一次元の配列を二次元の配列にする」と書きましたが、u が一次元配列になることはなさそうです。たとえば、次のように入力ベクトルと重みを定義したとします。
xm にダミーを追加してから wm.T との積を計算するとスカラーになってしまいます。
このような状況で func(u) に次元を与えるため、layer() の中身を記事本文にあるように書き直しました。
配列の次元のことばかり考えていたら、スカラーのときに ndim が 0 になることをすっかり忘れていました。でも、下記のように wm を 2 次元にして xm と内積をとると [2.5 6.5] の 1 次元配列か得られるので、1 次元の場合に2次元の配列に変換する処理も必要だと思います。
xm=np.array([1.0, 2.0, 1.0])
wm=np.array([[0.5, 0.5. 1.0],
[2.0, 3.0, -1.5]])
u=np.dot(xm, wm.T)
print(u)
wm は xm の各要素に対する重みなので勝手に形を決められるわけではなく、xm の形に依存します。たとえば、xm を
xm = np.array([1.0, 2.0, 1.0])
としたときは、これにダミー入力を加えると
xm = np.array([1.0, 2.0, 1.0, 1.0])
となるので、必要な重みは、
wm = np.array([0.5, 0.5, 1.0, 0.2])
のように 4 要素をもつ一次元配列となるはずです。
修正された In[1] プログラムを実行後に、入力データを 1 つにして X=np.array([.1, .2]) として In[2] プログラムを実行すると、1次元の [0.794 0.332] が得られますが、これはそのままでいいのでしょうか。
申し訳ないです! さきほどの私の回答は完全に間違っていました。記事本文をよく読み直さずに、b 層が 1 ユニットのモデルで考えていました。記事本文の図にあるような b 層が 2 ユニットの場合は重み行列は 2 次元配列になりますね。その場合は、前回の質問でおっしゃられていたように
のように、u が一次元配列になります。どのようなユニット数にも対応できるようにコードを変更しますので、しばらくお待ちください。本当に申し訳ありませんでした。
コードを修正しました。
たぶん、これで大丈夫だと思います。
色々な入力条件で動作をチェックしていただけると助かります。
よろしくお願いします。m(_ _)m
X, W をともに 1 次元、あるいはどちらかを 1 次元にしても OK でした。
ところで、なぜ layer( ) の戻り値を 2 次元の配列にそろえる必要があるのでしょうか。
動作確認していただいて、ありがとうございます。出力結果の次元を絶対に揃えなければならないということもないのですが、揃っていたほうがきれいだと思ったので … それだけです。あ、それから、このサイトのコメントは10階層までしか入れ子にできないので、このコメントに返信できなくなっています。次回以降は新しいコメントを作成してください。
単にニューラルネットワークを訓練するという目的であれば、出力結果の次元を気にする必要はありません。しかし、ニューラルネットワークの規模が大きいと、膨大な学習時間がかかり、メモリにも大きな負担がかかります。そのため、ネットワークからの出力値と、その時点で学習した重みと出力値を一時的に CSV ファイルなどに書き出して保存しておけば、一旦 PC を休ませて、後日また学習を再開させることもできます(バックプロパゲーションには現時点での出力値と学習した重みのデータが必要)。出力値の形式(次元など)が決まっていれば、ファイルへの書き出しのコードをシンプルにできるという利点があります。
【お詫び】In[3] と In[4] および、その説明文に誤りがありましたが、本筋に不要と判断して記事から割愛させていただきました。申し訳ありません。