検証曲線(validation curve)
scikit-learn回帰分析
これまでの記事では、ほとんどゼロからモデルを構築しながら色々な回帰分析の手法について学んできました。今回は回帰分析シリーズの締め括りとして、scikit-learn という機械学習専用ライブラリを使った線形回帰の手順を解説します。
今回の分析で用いるモジュールをまとめてインポートしておきます。
# https://python.atelierkobato.com/curve/ # リストM5-A-1 # scikit-learn回帰分析 # 必要なモジュールをインポート import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import validation_curve from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline
分析対象は、前回記事の最後のコードに掲載した 40個の年齢と体重のデータセットです。scikit-learn では入力データと目標データを行方向に並べるという決まりがあるので、x = x[:, np.newaxis] のように記述して、データを列ベクトル(1次元配列を縦に並べた 2次元配列)に変換します。
# https://python.atelierkobato.com/curve/
# リストM5-A-2
# scikit-learn回帰分析
# 入力データベクトル(年齢)
x = np.array([35, 16, 22, 43, 5,
66, 20, 13, 52, 1,
39, 62, 45, 33, 8,
28, 71, 24, 18, 3,
29, 37, 75, 56, 74,
51, 65, 29, 91, 54,
61, 52, 5, 64, 76,
63, 17, 78, 58, 12])
# 目標データベクトル(体重)
y = np.array([85.19, 58.93, 64.27, 68.91, 21.27,
68.88, 60.07, 55.18, 88.08, 8.89,
82.31, 81.18, 80.76, 78.98, 37.55,
75.9, 72.39, 69.51, 62.04, 12.47,
62.85, 85.5, 52.29, 46.71, 57.17,
74.54, 51.68, 40.45, 60.02, 75.28,
64.15, 60.56, 19.75, 55.13, 59.77,
63.95, 63.16, 56.37, 58.91, 42.09])
# xとyを列ベクトルに変形
x = x[:, np.newaxis]
y = y[:, np.newaxis]
# x軸方向の格子点を作成
x_mesh = np.linspace(0, 100, 100)
pipelineモジュールの make_pipeline() に PolynomialFeatures(n) と LinearRegression() を渡すと、n次多項式線形回帰の情報を備えた Pipelineクラスのインスタンスが生成されます。このインスタンスの fit()メソッドに入力データベクトルと目標データベクトルを渡すと、最適化されたパラメータを取得できます。以下のコードでは、for文を使って n に 1 ~ 8 の数字を与えて、それぞれの近似曲線を描きます。
# https://python.atelierkobato.com/curve/
# リストM5-A-3
# scikit-learn回帰分析
# フィギュアと4×2個のAxesを作成
fig, axes = plt.subplots(4, 2, figsize = (8, 12))
# それぞれのAxesについて、n=1~8次の多項式を使って最適化および曲線のプロットを実行
for ax, n in zip(axes.ravel(), [1, 2, 3, 4, 5, 6, 7, 8]):
# Pipelineオブジェクトを生成(n次多項式, 線形回帰)
pl = make_pipeline(PolynomialFeatures(n), LinearRegression())
# 訓練データによる最適化
pl.fit(x_train, y_train)
# 任意の年齢xに対する体重の予測式w(x)
w = pl.predict(x_mesh[:, np.newaxis])
# 入力データと目標データをプロット
ax.scatter(x_train, y_train, color = 'blue', s = 12)
# 近似曲線をプロット
ax.plot(x_mesh, w, color = 'red', linewidth = 1.2)
# 軸範囲と軸ラベル、タイトルを設定
ax.set_xlim(0, 100)
ax.set_ylim(0, 100)
ax.set_xlabel('Age')
ax.set_ylabel('Weight [kg]')
ax.set_title('degree = {}'.format(n))
fig.tight_layout()
plt.show()
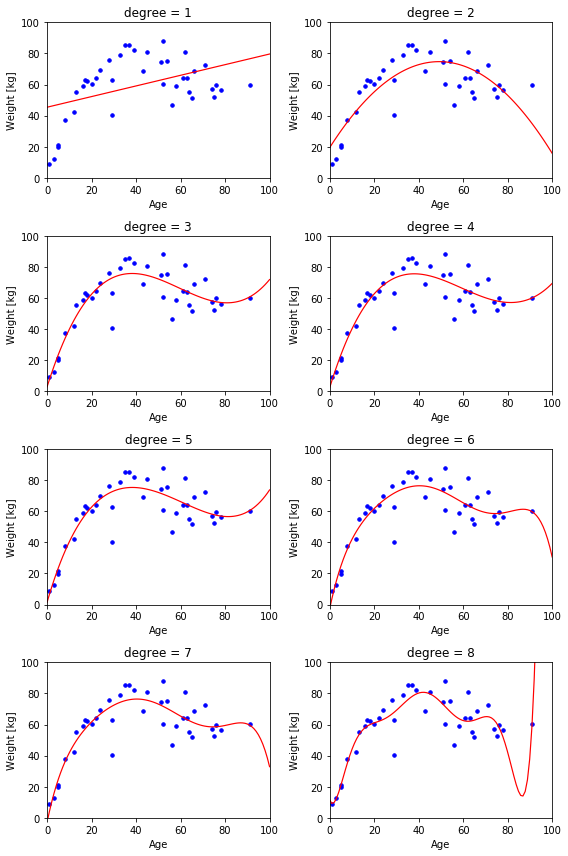
あくまで多項式の線形回帰なので、さほど高い精度は望めません。いずれの図を見ても 80歳以降で体重が増加したり、あるいは極端に低下していたりするので、モデルとして使用するならば適用年齢範囲を制限する必要があるでしょう。
検証曲線(validation curve)
とにかく、この中で一番良いモデルを探すために validation_curve() で 8分割交差検証曲線を描いてみます。
# https://python.atelierkobato.com/curve/
# リストM5-A-4
# scikit-learn回帰分析
# 多項式の次数[0,1,2,...,18]
deg = np.arange(0, 18)
# 8分割交差検証による訓練スコア配列と検証スコア配列
train_score, val_score = validation_curve(pl, x, y,
'polynomialfeatures__degree',
deg, cv = 8)
# 訓練スコア配列の列方向に沿った中央値(メジアン)
train_m = np.median(train_score, 1)
# 検証スコア配列の列方向に沿った中央値(メジアン)
val_m = np.median(val_score, 1)
# フィギュアとAxesを作成
fig, ax = plt.subplots(figsize = (8, 6))
# 横軸に次数をとって訓練スコアと検証スコアをプロット
ax.grid()
ax.set_title('Validation curve', fontsize = 16)
ax.set_xlabel('degree', fontsize = 14)
ax.set_ylabel('score', fontsize = 14)
ax.set_xlim(0, 18)
ax.set_ylim(-0.6, 1)
ax.plot(deg, train_m, color = 'b', label = 'training score')
ax.plot(deg, val_m, color = 'r', label = 'validation score')
ax.legend(loc = 'best')
plt.show()
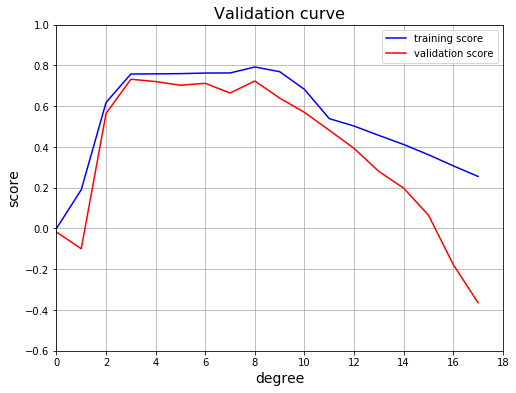
縦軸はフィッティング精度を表すスコアです。-1 から 1 の値をとるように規格化されていて、値が大きいほど最適化した曲線が目標データに適合していることを意味します。青いラインは曲線と訓練データの適合度を表す 訓練スコア であり、赤いラインは曲線と検証データの適合度を表す 検証スコア です。このグラフから、訓練スコアと検証スコアがいずれも高く、かつ互いに乖離していない次数3 の多項式が最も適切なモデルであると判断できます。
validation_curve() について補足しておきます。リストM5-A-4 では、すべての次数の訓練スコアと検証スコアを一度に取得していますが、たとえば deg の部分を [3] と書き換えて次のようなコードを書くと、3次の多項式モデルで 8分割交差検証を行なって、val_score には検証スコアが格納されます。
train_score, val_score = validation_curve(pl, x, y,
'polynomialfeatures__degree',
[3], cv = 8)
print(val_score)
# [[0.92540616 0.86061111 0.65492969 0.91236326
# 0.11521658 -0.56593278 0.80932356 0.56555209]]
ある分割データを検証データとして選択したときに、訓練データを使って作成した近似曲線と検証データとの間で適合度を計算しています。 今は 8分割交差検証を行なっているので、検証データの選び方は全部で 8通り、すなわち検証スコアの要素は全部で 8 個となります (詳しくは K-分割交差検証の記事 を参照してください)。
リストM5-A-4 では、この 8個の要素を大きさ順に並べたときに、真ん中にくる数字(中央値)を最終的な検証スコアとして採用しています。ただし、データが偶数個ある場合は真ん中に 2個の数字がくるので、その平均値を中央値とします。中央値は numpy.median() で取得することができます。第2引数で中央値をとる軸を選択します (1 を指定すると列方向です)。
print(np.median(val_score, 1)) # [0.73212662]
コメント