ガウス基底モデル
前回までは多項式近似を扱いましたが、今回は
\[\phi(x)=\exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\}\tag{1}\]
で定義される ガウス関数 を基底関数として用いた ガウス基底モデル を扱います。
$\sigma=10,\ \mu=20k\ (k=0,\ 1,\ 2,\ 3,\ 4)$ とした 5 個のガウス関数
\[\phi_k(x)=\exp\left\{-\frac{(x-20k)^2}{2\cdot 10^2}\right\}\quad (k=0,\ 1,\ 2,\ 3,\ 4)\tag{2}\]
および、定数関数 $\phi_5(x)=1$ の線形結合
\[\sum_{k=0}^{5}a_k\phi_k(x)\tag{3}\]
を近似関数として与えてパラメータ $a_k$ を最適化します。
def構文を使って $\mu$ が少しずつ異なる (2) を別々に定義するのは面倒です。そこで、「ガウス関数を生成する関数」を定義します。以下のコードは、前回記事 の In[1] と In[2] が実行済みの状態で動かしてください。
# In[3]
# μとσを与えてxのみを変数とするガウス関数を返す関数を定義
def gauss(mu=0, sigma=1):
def inner(x):
return np.exp(-(x - mu)**2 / (2 * sigma**2))
return inner
上のコードを実装して、gauss() に適当な mu と sigma を渡して実行すると、指定した $\mu$ と $\sigma$ が組み込まれた一変数ガウス関数が返ります。試しに、gauss() に mu=40, sigma=10 を渡して実行してみましょう。
# In[4] # μ=10,σ=40のガウス関数を生成 func = gauss(40, 10) print(func) # <function gauss..inner at 0x03B26C90>
実行結果をみると、gauss() のローカル関数オブジェクト inner が返っていることがわかります。func() に適当な数字を渡すと、ガウス関数の具体的な値を返します。
# In[5] # μ=10,σ=40,x=5のガウス関数の値 print(func(5)) # 0.002187491118182885
for構文を使って、(1) で定義される関数オブジェクトのリストを作成し、さらに定数関数を追加しておきます。
# In[6]
# 基底関数を収めるリスト
basis = []
# 基底関数のリストを作成
for i in range(5):
func = gauss(20*i, 10)
basis.append(func)
# 定数関数を追加
basis.append(lambda x:1)
それでは、パラメータを最適化してみましょう。
# In[7]
# Fit_funcオブジェクトを作成
z = Fit_func(x, y, basis)
# params()メソッドで最適化されたパラメータを取得
print("p = {}".format(z.params()))
# sd()メソッドで標準偏差を取得
sd = np.round(z.sd(), 3)
# FigureとAxes
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111)
# Axesのタイトルを設定
ax.set_title("Fit with 5 Gaussian basis", fontsize=16)
# テキストボックスの書式辞書を作成
boxdic = {"facecolor" : "white", "edgecolor" : "gray",}
# テキストボックスを表示
ax.text(3, 90, "SD = {}".format(sd),
size=14, linespacing=1.5, bbox=boxdic)
# 目盛線を表示
ax.grid()
# 軸範囲と軸ラベル
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
ax.set_xlabel("Age", fontsize=14)
ax.set_ylabel("Weight [kg]", fontsize=14)
# 身長と体重データの散布図
ax.scatter(x, y, color="blue")
# line()メソッドを用いて近似曲線を作成
x2 = np.linspace(0, 70, 100)
y2 = z.line(x2)
ax.plot(x2, y2, color="red")
plt.show()
# p = [-101.892 -38.274 -34.094 -30.118 -54.606 122.477]
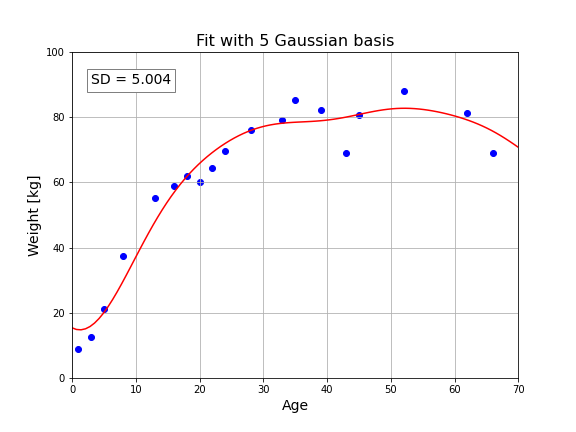
標準偏差は $5.004$ です。これは以前に扱った 2次関数モデルより少し良い近似ですが、2次関数と対数関数の混合基底モデルには及びません。ただし、基底の数を増やせば改良できるかもしれません。
オーバーフィッティング(過学習)
基底を増やせば、もっとデータにフィットするモデルを構築できると考えるかもしれません。確かにその通りなのですが、機械学習エンジニアを常に悩ませる問題が生じます。
まず任意の数 (n) の基底を生成する関数を用意します。
# In[8]
# ガウス基底生成関数
def gauss_basis(n, sigma):
basis = []
for i in range(n):
mu = (100/n) * i
func = gauss(mu, sigma)
basis.append(func)
return basis
gauss_basis() は平均値 $\mu$ を $n$ 等分して
\[\mu=\frac{100}{n}k\quad (k=0,\ 1,\ 2,\ \cdots,\ n-1)\tag{4}\]
のガウス基底を生成します。分散 $\sigma$ は自由に設定できます。ガウス基底の数を 1 個ずつ増やしながら、フィッティングの様子を調べてみましょう。
# In[9]
# FigureとAxes
fig, axs = plt.subplots(7, 1, figsize=(6, 30))
fig.subplots_adjust(hspace=0.3)
# カウンター(基底数)の初期値
i = 5
# 基底の数を増やしながらフィッティングの様子を調べる
for ax in axs.ravel():
i += 1
basis = gauss_basis(i, 10)
basis.append(lambda x:1)
z = Fit_func(x, y, basis)
ax.grid()
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
ax.set_title("n = {0}, SD = {1:.3f}".format(i, z.sd()), fontsize=14)
ax.set_ylabel("Weight [kg]", fontsize=14)
ax.scatter(x, y, color="blue")
x2 = np.linspace(0, 70, 100)
y2 = z.line(x2)
ax.plot(x2, y2, color="red")
# 一番下のグラフのx軸にラベルを添付
ax.set_xlabel("Age", fontsize=14)
plt.show()
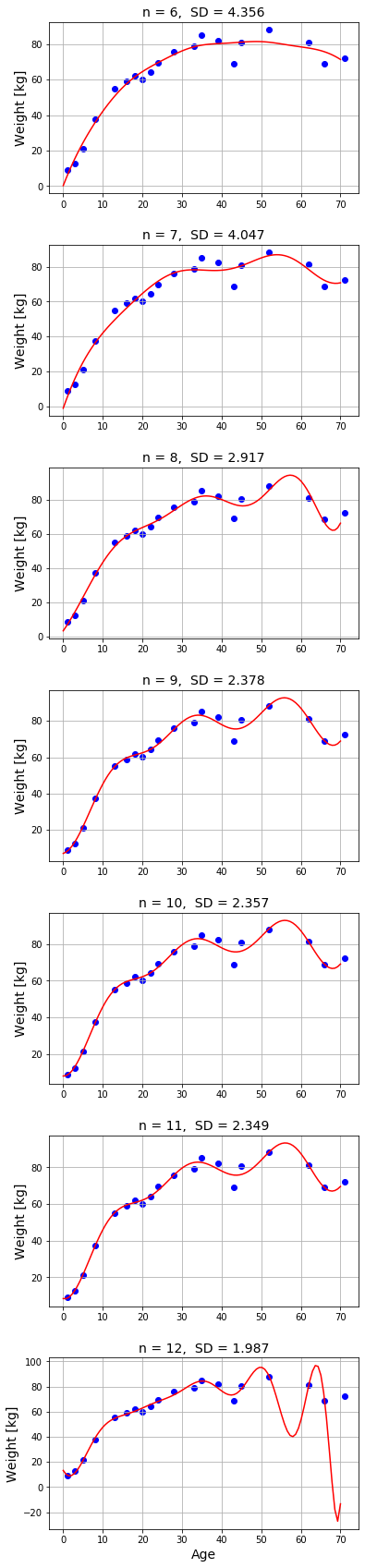
n はガウス基底の数です。これに定数関数が加わるので、実際には n + 1 個の基底を使って最適化しています。実行結果を見ると、n を増やすほど標準偏差 SD は確かに減少していきますが、n が 7 を超えたあたりから曲線は湾曲し始めて、n = 12 では収拾がつかない状態となっています。常識的に考えると、年齢と体重がこのような関係になるはずもありません。
これはデータのばらつきを曲線で表そうと頑張り過ぎた結果です。回帰アルゴリズムは標準偏差を減らす方向へパラメータを調整し続けます。つまり、モデルが柔軟なほど (基底が多いほど)、すべての点を近似曲線に乗せるように最適化しようとするので、最終的には湾曲部の多い不自然な曲線になってしまいます。
このような現象を過学習(オーバーフィッティング : over-fitting)といいます。特にガウス基底を単純に増やし続けると、最適化した係数が異常に大きな値になってしまう傾向があります。
コメント
下記は誤植と思われますので、ご確認ください。
In[4] プログラムの上の文で、gausee_maker( ) → gauss( )
In[4] プログラムの先頭に、import numpy as np を追加。
※ In[4] ではエラーは発生しないが、In[5] で発生します。
In[7] プログラムの実行するためには、前項の記事の In[1] プログラムの読み込みと In[2] プログラムの入力データベクトルと目標データベクトルの読み込みが必要です。
In[7] プログラムの実行結果のグラフが異なります。
この記事のコードは、前回記事の In[1] と In[2] が実行済みであることが前提となっています (なので In[3] から始まっています)。さらにこの記事では In[9] まで掲載していますが、次回記事では In[10] から掲載されます。機械学習はどうしてもコードが長くなるので、コードを全て再掲載するわけにもいかず、このような書き方をせざるをえませんでした。このことを明示しておかなかったのは申し訳なかったです。記事にコードを実行する前提条件を加筆しておきました m(_ _)m
In[7] のグラフを正しい図に差し替えておきました。
In[9] プログラムの
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
は、for文の中に入れたほうがいいと思います。そうすれば In[8] プログラムを実行していなくてもエラーが発生しません。
修正しておきました m(_ _)m