
ホールドアウト検証
前回記事で説明したオーバーフィッティング問題を解消する方法の1つがホールドアウト検証と呼ばれる手法です。
ホールドアウト検証はデータを学習データ (訓練データ) とテストデータに分けておき、学習データのみを使ってパラメータを最適化します。そして、最適化された近似曲線とテストデータを比較して、モデルの予測精度を検証します。
データの分割方法は色々ありますが、ここではデータの 4 分の 3 を学習データ、残りの 4 分の 1 をテストデータとして分けてみます。
# In[10] # 学習データ x_train = x[int(len(x)/4):] y_train = y[int(len(y)/4):] # テストデータ x_test = x[:int(len(x)/4)] y_test = y[:int(len(y)/4)]
入力データが分割されていることを確認しておきましょう。
# In[11]
print("x_train:\n{}\n".format(x_train))
print("x_test:\n{}".format(x_test))
# x_train:
# [66 20 13 52 1 39 62 45 33 8 28 71 24 18 3]
# x_test:
# [35 16 22 43 5]
今回は $n$ 個の ガウス関数 と定数関数、および対数関数 $\log(1+x)$ を基底とするモデルで、$n$ を変えながらフィッティングの精度を比較します。
# In[12]
# FigureとAxes
fig, axs = plt.subplots(8, 1, figsize=(5, 40))
fig.subplots_adjust(hspace=0.3)
# カウンター(基底数)の初期値
i = 0
# 基底の数を増やしながらフィッティングの様子を調べる
for ax in axs.ravel():
basis = gauss_basis(i, 10)
basis.append(lambda x:1)
basis.append(lambda x: np.log(1+x))
z = Fit_func(x_train, y_train, basis)
# テストデータの平均2乗誤差と標準偏差
mse_test = np.mean((z.line(x_test)-y_test)**2)
sd_test = np.sqrt(mse_test)
ax.grid()
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
ax.set_title("n={0}, SD_train={1:.3f}, SD_test={2:.3f}"
.format(i, z.sd(), sd_test), fontsize=14)
ax.set_ylabel("Weight [kg]", fontsize=14)
ax.scatter(x_train, y_train, color="blue")
ax.scatter(x_test, y_test, color="orange")
x2 = np.linspace(0, 70, 100)
y2 = z.line(x2)
ax.plot(x2, y2, color="red")
# カウンターを1つ増やす
i += 1
# 一番下のグラフのx軸にラベルを添付
ax.set_xlabel("Age", fontsize=14)
plt.show()
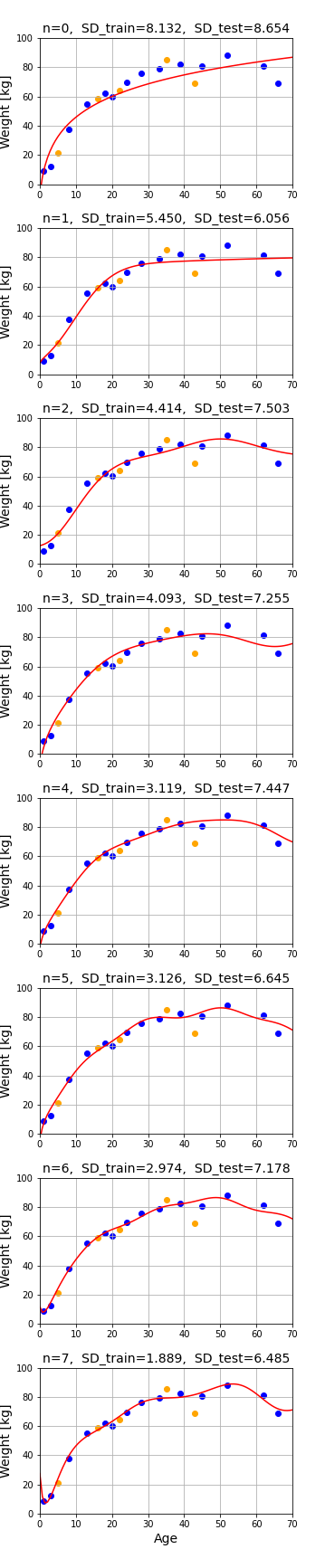
SD_train は学習データに対する標準偏差です。これはガウス基底の数 n を増やすほど減少していきます。しかし、大切なのは未知のデータに対する予測精度 (汎化性能) です。テストデータはフィッティングに用いられていないので、このモデルにとって未知のデータであり、SD_test (テストデータに対する標準偏差) は汎化性能の指標となります。
n = 1 のとき、SD_test は最小となっています。つまりガウス関数1つと、対数関数、定数関数の組み合わせが最良のモデルであるということです。ただし、これは1つの分割方法によって得られた結果なので、確証を得るためにはもう少し工夫が必要です。次回記事では分割方法を変えながらモデルをチェックする方法を解説します。
コメント
In[10] プログラムの
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
は for 文の中に入れたほうがいいと思います。
実行結果のグラフのオレンジ色のプロットが x_text と異なります。そのせいで SD_train とSD_test の値も違っていますので、ご確認ください。
申し訳ないです。
別のコードの実行結果を載せてしまっていたようです。
グラフを正しい図に差し替えておきました(axesの数は8に減らしておきました)。
for 文の外の
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
は、不要になりますのでご確認ください。
ありがとうございます。
修正しておきました。