
Irisデータセット
機械学習用ライブラリ scikit-learn には練習用データセットがいくつか用意されています。その中の 1 つ、Iris flower data set には、Iris(アヤメ属)に属する 3 品種、setosa(セトサ)、versicolor(バージカラー)、versinica(バージニカ)の特徴量測定値とクラスデータ(品種データ)が収められています。

[画像はアイキャッチも含めて Wikipedia から引用しています]
今後しばらくは、この Irisデータを使ってニューラルネットワークに品種分類を学習させるので、今回はデータを読み込んで、ネットワークに入力できるようにデータ構造を整えておきます。
Irisデータの読み込みと加工
最初に scikit-learn の datasets モジュールをインポートして、iris のデータを読み込みます。
# In[10] from sklearn import datasets # irisデータをロード iris = datasets.load_iris() # irisのがくの長さ、がくの幅、花びらの長さ、花びらの幅 data_in = iris.data # Setosa,Versicolor,Versinicaのクラスデータ data_c = iris.target
iris.data には、sepal length (がくの長さ)、sepal width (がくの幅)、petal length (花弁の長さ)、petal width (花弁の幅) の測定値が収められています。データの 5 行目までを表示してみます)。
# In[11] # data_inを5行目までを表示 print(data_in[:5]) ''' [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]] '''
iris.target はクラスデータ (品種データ) です。
setosa = 0, versicolor = 1, virginica = 2 で区分されています。
# In[12] # data_cを表示 print(data_c) ''' [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] '''
ただし、このままではネットワークに入力できないので、次のコードで 1 of K (one hot) 表記に変換しておきます。
# In[13] # data_cをone of Kに変換 data_c = np.identity(3, dtype = "int8")[data_c]
data_c の中身を確認しておきましょう。
# In[14] # 変更されたdata_cを5行目まで表示 print(data_c[:5]) ''' [[1 0 0] [1 0 0] [1 0 0] [1 0 0] [1 0 0]] '''
学習を安定させるために、data_in を「標準化」しておきます。
# In[15] # 入力データの平均値 data_in_av = np.average(data_in, axis = 0) # 入力データの標準偏差 data_in_sd = np.std(data_in, axis = 0) # 入力データの標準化 data_in = (data_in - data_in_av) / data_in_sd
最後に data_in と data_c を訓練データとテストデータに分割しておきます。
# In[16] # インデックス配列を作成 np.random.seed(10) idx = np.arange(len(data_c)) np.random.shuffle(idx) idx_train = idx[idx % 2 == 0] idx_test = idx[idx % 2 != 0] # 入力データを訓練データとテストデータに分割 data_in_train = data_in[idx_train] data_in_test = data_in[idx_test] # クラスデータを訓練データとテストデータに分割 data_c_train = data_c[idx_train] data_c_test = data_c[idx_test]
Irisのクラス分布
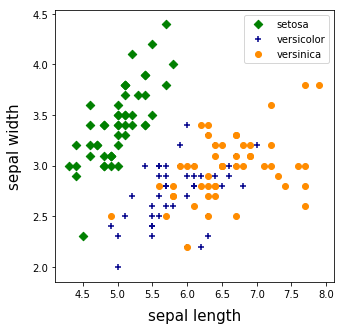
Iris のクラス分布の様子も見ておきましょう。今回は特徴量が 4 種類あるので、「がくの長さ」と「がくの幅」、「花弁の長さ」と「花弁の幅」の組合わせで 2 枚のマップを作ることにします。
「がくの長さ」と「がくの幅」のクラス分布描画コードです。
# In[17]
# setosaの「がくの長さ」と「がくの幅」を抽出
x1 = data_in[data_c[:,0] == 1][:, 0]
y1 = data_in[data_c[:,0] == 1][:, 1]
# versicolorの「がくの長さ」と「がくの幅」を抽出
x2 = data_in[data_c[:,1] == 1][:, 0]
y2 = data_in[data_c[:,1] == 1][:, 1]
# versinicaの「がくの長さ」と「がくの幅」を抽出
x3 = data_in[data_c[:,2] == 1][:, 0]
y3 = data_in[data_c[:,2] == 1][:, 1]
# 「がくの長さ」と「がくの幅」のクラス分布
fig = plt.figure(figsize = (5, 5))
ax = fig.add_subplot(111)
ax.set_xlabel("sepal length", size = 15, labelpad = 10)
ax.set_ylabel("sepal width", size = 15, labelpad = 10)
ax.scatter(x1, y1, marker = "D", color = "green", label = "setosa")
ax.scatter(x2, y2, marker = "+", color = "darkblue", label = "versicolor")
ax.scatter(x3, y3, marker = "o", color = "darkorange", label = "versinica")
ax.legend()
plt.show()
「花弁の長さ」と「花弁の幅」のクラス分布描画コードです。
# In[18]
# setosaの「花弁の長さ」と「花弁の幅」を抽出
x1 = data_in[data_c[:,0] == 1][:, 2]
y1 = data_in[data_c[:,0] == 1][:, 3]
# versicolorの「花弁の長さ」と「花弁の幅」を抽出
x2 = data_in[data_c[:,1] == 1][:, 2]
y2 = data_in[data_c[:,1] == 1][:, 3]
# versinicaの「花弁の長さ」と「花弁の幅」を抽出
x3 = data_in[data_c[:,2] == 1][:, 2]
y3 = data_in[data_c[:,2] == 1][:, 3]
# 「花弁の長さ」と「花弁の幅」のクラス分布
fig = plt.figure(figsize = (5, 5))
ax = fig.add_subplot(111)
ax.set_xlabel("petal length", size = 15, labelpad = 10)
ax.set_ylabel("petal width", size = 15, labelpad = 10)
ax.scatter(x1, y1, marker = "D", color = "green", label = "setosa")
ax.scatter(x2, y2, marker = "+", color = "darkblue", label = "versicolor")
ax.scatter(x3, y3, marker = "o", color = "darkorange", label = "versinica")
ax.legend()
plt.show()
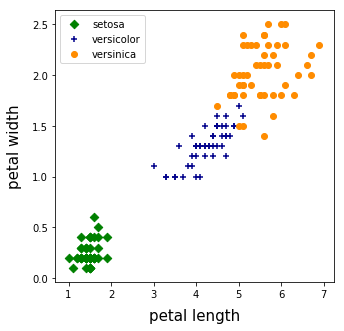
がくも花弁も、セトサは他の品種とは大きく異なる特徴を示しています。バージカラーとバージニカを比較すると、がくの特徴量にはほとんど差がありませんが、花弁の特徴量の境界は比較的明瞭です。
コメント