確率的勾配降下法(SGD)
下図のように、入力層、中間層、出力層がそれぞれ 1 層ずつからなるニューラルネットワークを構築します。
中間層の活性化関数は ReLU を採用します。
すでに部品は揃っているので、ネットワークの構築は簡単な作業です。
以下のように記述するだけで、ニューロン 5 個の中間層とニューロン 2 個の出力層が用意されます
mid = Middle_layer(2, 5, ReLU) out = Output_layer_c(5, 2)
ネットワークの稼働も簡単です。入力データ x が用意されているとして、
mid.forward(x)
と記述すれば、入力層から中間層にデータが入力され、中間層から活性化関数によって調整された信号が出力されます。その出力値は
mid.y_out
で取得できるので、この信号と正解値データ t を出力層に渡します:
out.activate(mid.y_out, t)
すると出力層は逆信号を送ってくるので、これを再び中間層が受け取ります:
mid.backward(out.y_back)
逆伝播によって各層で重みの更新も行なわれるので、上の手順を繰り返すことによって学習を進めることができます。
以下のコードでは、前回記事で作成した data_in (入力値) と data_c (正解値) のセットから無作為に 1 組ずつ取り出してネットワークに入力し、重みの更新を繰り返します。
このように、更新ごとにサンプルからランダムにデータを選んで学習に当てる手法を確率的勾配降下法(SGD:stochastic gradient descent)とよびます。確率的勾配降下法を使うと、データセット全体を使って計算される勾配とは若干異なる方向に進むので、局所的最適解に囚われにくいというメリットがあります(極小値のあたりをジグザグに進むので、浅い窪みであれば脱出できる可能性があります)。
# In[9]
# 確率的勾配降下法
# 乱数を初期化
np.random.seed(11)
# 学習率を設定
alpha = 0.01
# epochを設定
epoch = 18
# データの個数
nd = data_in.shape[0]
# インデックス配列
idx = np.arange(nd)
# 中間層と出力層を作成
mid = Middle_layer(2, 5, ReLU)
out = Output_layer_c(5, 2)
# FigureとAxesを用意
fig, axs = plt.subplots(9, 2, figsize = (12, 60))
# エポック数だけ学習を繰り返す
for ax, j in zip(axs.ravel(), range(epoch)):
# インデックスをシャッフル
np.random.shuffle(idx)
# オンライン学習
for k in idx:
mid.forward(data_in[k : k + 1])
out.activate(mid.y_out, data_c[k : k + 1])
mid.backward(out.y_back)
# 中間層にすべてのデータを入れる
mid.forward(data_in)
# ネットワークからの出力値を取得
out.forward(mid.y_out)
# 出力値をクラスデータに変換
y_class = np.argmax(out.y_out, axis = 1)
# クラスデータを1 of K(one-hot)表記に変換
y_class_01 = np.identity(2, dtype = "int8")[y_class]
# 放物線の上側にある座標
# クラスデータの1列目が1となっているデータを抽出
x1 = data_in[y_class_01[:,0] == 1][:, 0]
y1 = data_in[y_class_01[:,0] == 1][:, 1]
# 放物線の下側にある座標
# クラスデータの1列目が0となっているデータを抽出
x2 = data_in[y_class_01[:,0] == 0][:, 0]
y2 = data_in[y_class_01[:,0] == 0][:, 1]
# 境界線のデータ
x3 = np.linspace(-6, 6, 33)
y3 = x3**2 - 4
# クラス分布を表示
ax.set_title("epoch = {}".format(j + 1), size = 15)
ax.set_xlim([-6, 6])
ax.set_ylim([-6, 6])
ax.scatter(x1, y1,marker = "D", color = "darkorange")
ax.scatter(x2, y2, marker = "+", color = "darkblue")
ax.plot(x3, y3, color = "black")
plt.show()
コードを実行すると、学習過程を追ってエポックごとのクラス分布が表示されます。
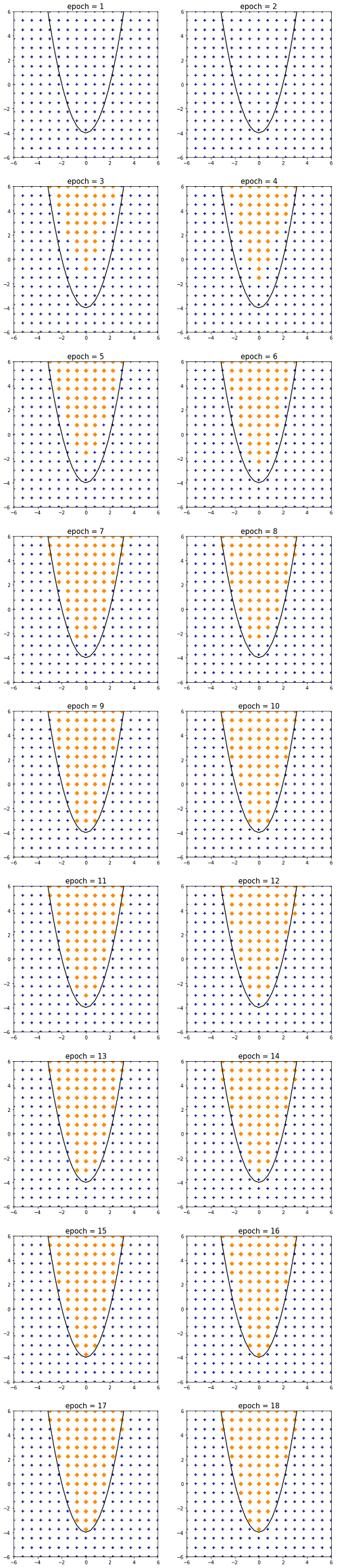
完全に分類に成功しているわけではありませんが、15 エポックあたりでほぼ最適化を完了しています。ニューラルネットワークでは、学習率や中間層の数、各層のニューロン数などのパラメータを少し変えるだけで、学習速度や分類精度が変化するので、色々と試してみてください。
コメント