学習用データの作成
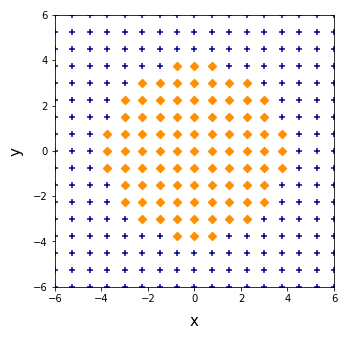
ニューラルネットワーク を試験運用するための簡単な学習用データを作成しておきます。入力データは $xy$ 平面の座標とします。正解値(目標変数)は、放物線 $y=x^2-4$ の上側にある点と下側にある点を、それぞれ 1 と 0 で表した 1 of K 表記のデータです。
# In[7] # ★★★ 座標データを作成 ★★★ x = np.linspace(-6, 6, 17) y = np.linspace(-6, 6, 17) xx, yy = np.meshgrid(x, y) XX, YY = np.meshgrid(x, y) # ★★★ 入力データの作成 ★★★ # 格子データを1次元配列に変換 x_in = xx.reshape(-1) y_in = yy.reshape(-1) # x_inとy_inを結合 data_in = np.vstack([x_in, y_in]).T # ★★★ クラスデータの作成 ★★★ # 条件を設定 condition = YY >= XX**2 - 4 # クラスデータの1列目 # 条件を満たすデータを1に、満たさないデータを0に書き換える XX[condition] = 1 XX[~condition] = 0 # クラスデータの2列目 # 条件を満たすデータを0に、満たさないデータを1に書き換える YY[condition] = 0 YY[~condition] = 1 # 格子データを1次元配列に変換 X = XX.reshape(-1) Y = YY.reshape(-1) # one_of_Kのクラスデータ data_c = np.vstack([X, Y]).T
In[7] について簡単に解説しておきます。numpy.meshgrid() で 2 セットの格子データを生成します。xx と yy は形状を 1 次元配列に変換した後で、numpy.vstack() で縦軸 (axis = 0) 方向に結合して入力データ data_in とします。放物線 $y=x^2-4$ の(境界線も含めて)上側にある条件は
\[y\geq x^2-4\]
と表せます。格子点データ XX と YY について、
condition = XX**2 + YY**2 <= 16
という条件式 condition を定義して、
XX[condition] = 1
で条件を満たすデータをすべて 1 に書き換えます。Python でブール値 (True または False) を反転させる演算子は「 ~ 」です。すなわち、~conditon は条件を満たさない(放物線の下側にある)ことを意味します。したがって、
XX[~condition] = 0
と記述すると、条件を満たさないデータは 0 に書き換えられます。これで、XX はクラスデータの 1 列目となりました。同様に YY を使ってクラスデータの 2 列目を作成します (YY は XX の 0 と 1 を反転させた配列です) 。XX と YY を 1 次元配列に変換して、numpy.vstack() で結合させると、正解値データの完成です。
XX[condition] = 1 で XX が書き換えられているのに、XX を含んだ condition を使って YY のデータを作成していいのかと不安になるかもしれません(私も少し不安になりました)が、condition には、この変数を定義したときの XX の状態が保存されているので問題ありません。念のために、データを平面にプロットして確認しておきましょう。
# In[8]
import matplotlib.pyplot as plt
# 放物線の上側にある座標
# クラスデータの1列目が1となっているデータを抽出
x1 = data_in[data_c[:,0] == 1][:, 0]
y1 = data_in[data_c[:,0] == 1][:, 1]
# 放物線の下側にある座標
# クラスデータの1列目が0となっているデータを抽出
x2 = data_in[data_c[:,0] == 0][:, 0]
y2 = data_in[data_c[:,0] == 0][:, 1]
# 正解データをプロット
fig = plt.figure(figsize = (5, 5))
ax = fig.add_subplot(111)
ax.set_xlabel("x", size = 15, labelpad = 10)
ax.set_ylabel("y", size = 15, labelpad = 10)
ax.set_xlim([-6, 6])
ax.set_ylim([-6, 6])
ax.scatter(x1, y1, marker = "D", color = "darkorange")
ax.scatter(x2, y2, marker = "+", color = "darkblue"
次回記事のニューラルネットワーク試験運用では、このデータを使います。
コメント