線形回帰モデル② 最小二乗法による単回帰分析
前回記事では年齢データ $x_k$ と体重データ $y_k$ をもとに、
\[Q(a,b)=\frac{1}{N}\sum_{k=0}^{N-1}\{w(x_k)-y_k\}^2=\frac{1}{N}\sum_{k=0}^{N-1}(ax_k+b-y_k)^2\tag{1}\]
を最小にするような $a,\ b$ を勾配法のアルゴリズムで計算させて、年齢 $x$ と体重 $w$ の関係式(近似直線)
\[w(x)=ax+b\tag{2}\]
を決定しました。しかし、パラメータ $a,\ b$ は 最小二乗法 という手順によって厳密解(解析解)が得られることが知られています。理工系の人にとっては、実験データの分析などでおなじみの古典的手法です。偏微分によって $Q$ の極値を求める方法が一般的ですが、ここでは線形代数学の概念のみを用いたエレガントな手法を解説します。
$N$ 個の要素からなる入力データベクトル $\boldsymbol{x}$ と目標データベクトル $\boldsymbol{y}$、および全ての要素が $1$ である $N$ 次元ベクトル $\boldsymbol{t}$ を定義します。
\[\boldsymbol{x}=\begin{bmatrix}x_0\\x_1\\\vdots\\x_{N-1}\end{bmatrix},\quad\boldsymbol{y}=\begin{bmatrix}y_0\\y_1\\\vdots\\y_{N-1}\end{bmatrix},\quad\boldsymbol{t}=\begin{bmatrix}1\\1\\\vdots\\1\end{bmatrix}\tag{3}\]
入力ベクトル $\boldsymbol{x}$ を与えたとき、目標データが
\[\boldsymbol{w}(\boldsymbol{x})=a\boldsymbol{x}+b\boldsymbol{t}\tag{4}\]
となるようなベクトル関数 $\boldsymbol{w}(\boldsymbol{x})$ を定義して、現実の目標データベクトル $\boldsymbol{y}$ との差分ベクトル
\[\boldsymbol{y}-\boldsymbol{w}(\boldsymbol{x})=\boldsymbol{y}-a\boldsymbol{x}-b\boldsymbol{t}=\begin{bmatrix}
y_0-ax_0-b\\y_1-ax_1-b\\\vdots\\y_{N-1}-ax_{N-1}-b\end{bmatrix}\tag{5}\]
を考えて、各成分の平方和 (2乗和) が最小となるようなパラメータ $a,\ b$ を探します。すなわちベクトル $\boldsymbol{y}-\boldsymbol{w}(\boldsymbol{x})$ の大きさの 2乗
\[L(a,b)=|\boldsymbol{y}-\boldsymbol{w}(\boldsymbol{x})|^2=|\boldsymbol{y}-(a\boldsymbol{x}+b\boldsymbol{t})|^2\tag{6}\]
が最小になるように $a,\ b$ を決定します。$a\boldsymbol{x}+b\boldsymbol{t}$ は、$N$ 次元空間内で $\boldsymbol{x}$ と $\boldsymbol{t}$ が張る平面 $S$ の上を動くベクトルです。このベクトルが表す点を $\mathrm{P}$ とします。
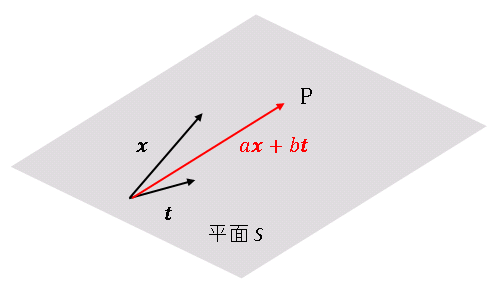
$\boldsymbol{y}$ は $N$ 次元空間内の固定された点です。この点を $\mathrm{Q}$ とおくと、
\[\vec{\mathrm{PQ}}=\boldsymbol{y}-(a\boldsymbol{x}+b\boldsymbol{t})\tag{7}\]
となります。$|\vec{\mathrm{PQ}}|$ が最小となるような点 $\mathrm{P}$ は、$\mathrm{Q}$ から平面に下ろした垂線の足です。
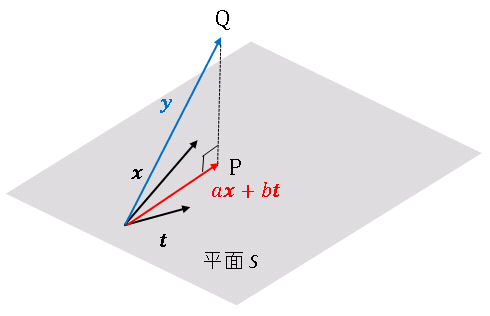
このとき、$\vec{\mathrm{PQ}}$ は $\boldsymbol{x}$ と $\boldsymbol{t}$ の両方に対して垂直になっています。すなわち
\[\begin{align*}(\boldsymbol{y}-a\boldsymbol{x}-b\boldsymbol{t})\cdot\boldsymbol{x}&=0 \tag{8}\\[6pt](\boldsymbol{y}-a\boldsymbol{x}-b\boldsymbol{t})\cdot\boldsymbol{t}&=0\tag{9}\end{align*}\]
が成り立ちます。式を整理すると、
\[\begin{align*}a\boldsymbol{x}\cdot\boldsymbol{x}+b\boldsymbol{t}\cdot\boldsymbol{x}&=\boldsymbol{x}\cdot\boldsymbol{y}\tag{10}\\[6pt]a\boldsymbol{x}\cdot\boldsymbol{t}+b\boldsymbol{t}\cdot\boldsymbol{t}&=\boldsymbol{y}\cdot\boldsymbol{t}\tag{11}\end{align*}\]
目的は $a,\ b$ を求めることです。パラメータベクトル
\[\boldsymbol{p}=\begin{bmatrix}a\\b\end{bmatrix}\tag{12}\]
を定義して、上の連立方程式を行列形式で表すと
\[\begin{bmatrix}\boldsymbol{x}\cdot\boldsymbol{x} &\boldsymbol{x}\cdot\boldsymbol{t}\\\boldsymbol{x}\cdot\boldsymbol{t} & \boldsymbol{t}\cdot\boldsymbol{t}\end{bmatrix}\begin{bmatrix}a\\b\end{bmatrix}=\begin{bmatrix}\boldsymbol{x}\cdot\boldsymbol{y}\\
\boldsymbol{y}\cdot\boldsymbol{t}\end{bmatrix}\tag{13}\]
と表せます。このまま逆行列を計算すれば $a,\ b$ を求めることはできますが、ここでは Python で実装しやすいように、もう少し変形を続けます。簡単のために $N=3$ として(一般の $N$ でも以下の操作は同じです)、左辺に現れた行列をベクトルの成分で書き表すと
\[\begin{bmatrix}\boldsymbol{x}\cdot\boldsymbol{x} & \boldsymbol{x}\cdot\boldsymbol{t}\\
\boldsymbol{x}\cdot\boldsymbol{t} & \boldsymbol{t}\cdot\boldsymbol{t}\end{bmatrix}
=\begin{bmatrix}x_0^2+x_1^2+x_2^2 & x_0t_0+x_1t_1+x_2t_2\\x_0t_0+x_1t_1+x_2t_2 & t_0^2+t_1^2+t_2^2\end{bmatrix}\tag{14}\]
となります。この行列は次のように分解できます。
\[\begin{bmatrix}x_0 & x_1 & x_2\\t_0 & t_1 & t_2\end{bmatrix}\begin{bmatrix}x_0 & t_0\\x_1 & t_1\\x_2 & t_2\end{bmatrix}\tag{15}\]
ここで $3$ 行 $2$ 列の行列 $X$ を
\[X=\begin{bmatrix}x_0 & t_0\\x_1 & t_1\\x_2 & t_2\end{bmatrix}\tag{16}\]
のように定義すると、
\[\begin{bmatrix}x_0 & x_1 & x_2\\t_0 & t_1 & t_2\end{bmatrix}
\begin{bmatrix}x_0 & t_0\\x_1 & t_1\\x_2 & t_2\end{bmatrix}=X^T X\tag{17}\]
と表せます。$X^T$ は $X$ の行と列を入れ替えた転置行列です。同様に式 (13) の右辺を成分表記すると
\[\begin{bmatrix}\boldsymbol{x}\cdot\boldsymbol{y}\\\boldsymbol{y}\cdot\boldsymbol{t}\end{bmatrix}
=\begin{bmatrix}x_0y_0+x_1y_1+x_2y_2\\t_0y_0+t_1y_1+t_2y_2\end{bmatrix}\tag{18}\]
と表せますが、これは次のような行列の積の形に書き直せます。
\[\begin{bmatrix}x_0 & x_1 & x_2\\t_0 & t_1 & t_2\end{bmatrix}\begin{bmatrix}y_0\\y_1\\y_2\end{bmatrix}\tag{19}\]
これは $X$ の転置行列を用いて $X^T\boldsymbol{y}$ と表せます。以上より、式 (13) は
\[(X^T X)\boldsymbol{p}=X^T\boldsymbol{y}\tag{20}\]
と表すことができるので、両辺に左側から $X^T X$ の逆行列をかけると、
\[\boldsymbol{p}=(X^T X)^{-1}X^{T}\boldsymbol{y}\tag{21}\]
というように、パラメータベクトルを決定することができます。$(X^T X)^{-1}X^{T}$ はムーア-・ペンローズの疑似逆行列 (pseudo-inverse matrix)、あるいは一般化逆行列 (generalized inverse matrix) とよばれる行列で、正方行列でなくても逆行列のように扱えます。逆行列や転置行列は NumPy の配列属性や関数を使って簡単に求めることができます。
単回帰分析 (目標データを1つの入力変数で説明する近似手法) に限るなら、パラメータを決定するために、ここまで凝ったことをする必要はありません。しかし、入力データの種類が増えたり、基底関数近似を扱うときにも同じ方法が使えるので、汎用性の高い手法といえます。もう少し先に進むと、その恩恵を実感できるので、今のうちに行列計算に慣れておいてください。
前回記事と同じ年齢 $\boldsymbol{x}$ と体重 $\boldsymbol{y}$ のデータを使って、$a,\ b$ を計算してみましょう。
# Least_squares_method
# In[1]
import numpy as np
# 疑似逆行列関数を定義
def pseudo_inverse(x):
return np.linalg.inv(x.T @ x) @ x.T
# 20人の年齢と体重のデータセット
# 年齢は25歳以下に限定
x = np.array([9, 21, 6, 18, 5,
6, 7, 12, 10, 20,
17, 3, 24, 9, 18,
23, 12, 13, 16, 13])
y = np.array([29.01, 78.1, 18.78, 57.94, 14.81,
22.34, 26.31, 41.69, 35.25, 60.92,
69.08, 16, 66.39, 27.06, 68.03,
61.45, 42.07, 40.64, 59.62, 32.22])
# xとt=[1,1,...1]をまとめて行列にする
X = np.array([x, np.ones(len(x))]).T
# Xの疑似逆行列を求める
pi_X = pseudo_inverse(X)
# パラメータベクトルの決定
p = pi_X @ y
print(p)
# [3.00922779 3.9646159]
前回とほぼ同じ結果が表示されます。年齢 $x$ と体重 $w(x)$ の関係は
\[w(x) = 3.0092x + 3.9646\tag{22}\]
で表されることになります。たとえば、年齢が 21 歳である場合には、
\[w(21)=3.0092\times 21+3.9646=67.2[\mathrm{kg}]\tag{23}\]
となります。
コメント
下記は誤植と思われますので、ご確認ください。
(4),(6),(7) 式で、ax-bt → ax+bt
(5) 式で、ax-bt → y-ax-bt
(12) 式の右辺のベクトルの ( ) → [ ]
(17) 式の下の文章で、式 (1) の右辺 → 式 (13) の右辺
線形代数の新着記事「ケーリー・ハミルトンの定理」をアップしました。お時間のある時にお立ち寄りください。m(_ _)m
それにしても学習ペースが速いですね。
微積分や線形代数を前提とするので、決して易しくはない内容のはずなんですが…
理工学部の学生さんでしょうか?
大切なお時間を使って記事の訂正にご協力いただき、本当にありがとうございます。m(_ _)m