
【Python統計学】中央値(メジアン)
データを昇順(小さい順)あるいは降順(大きい順)に並べたときに真ん中にくる値を中央値(メジアン)と定義します。たとえば、昇順に並んだ 9 個のデータ
1, 3, 7, 10, 13, 15, 19, 23, 28
の中央値は、左から(あるいは右から)数えて 5 番目にある 13 です。
データが偶数個のときは真ん中にある 2 数の平均値を中央値とします。たとえば、10 個のデータ
5, 9, 13, 21, 40, 46, 55, 69, 71, 98
の真ん中には $40$ と $46$ の値があるので、その平均をとって中央値は $43$ となります。
正規分布で近似できるような左右対称形データの中央値は平均値に近い値をとります。たとえば、大勢の人が受けた試験の得点を考えるとき、平均点をとった人は、おおよそ真ん中あたりの順位にいると判断できます。
30 人が受けた試験の得点分布が次のように与えられたとします。
# PYTHON_MEDIAN
# In[1]
# テストの得点分布
score = [91, 71, 79, 98, 93, 50, 79, 62, 63, 71,
67, 86, 76, 66, 71, 70, 87, 61, 69, 52,
26, 74, 77, 53, 99, 43, 65, 62, 87, 87]
NumPy と Matplotlib をインポートして、ヒストグラムを描き、分布の概観を確認します。
# In[2]
import numpy as np
import matplotlib.pyplot as plt
# FigureとAxes
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111)
ax.set_xlabel("Score", fontsize = 15)
ax.set_ylabel("Frequency", fontsize = 15)
ax.set_xlim(0, 100)
# ヒストグラムを描画
ax.hist(score, range=(0,100), color = "red")
# グラフを描画
plt.show()
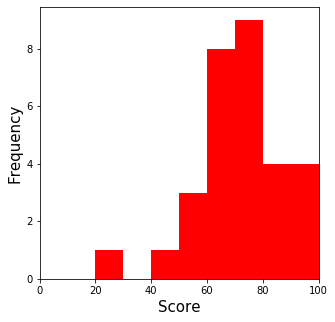
データ数が少ないので、正規分布からほど遠い粗い形とはなっていますが、このぐらいの対称性があれば、中央値と平均値は近い値をとります。numpy.median() と numpy.mean() で中央値と平均値を計算してみます。
# In[3]
# 得点の中央値
median_score = np.median(score)
# 得点の平均値
mean_score = np.mean(score)
print("得点の中央値: {:.1f}".format(median_score))
print("得点の平均値: {:.1f}".format(mean_score))
# 得点の中央値: 71.0
# 得点の平均値: 71.2
つまり、平均点をとった人はおおよそ 15 ~ 16 番目の順位にあると考えることができます。
左右非対称な分布においては、中央値と平均値の差は大きくなります。
たとえば、日本国民の世帯当たりの貯蓄額は非対称分布となっています。
貯蓄格差のやや極端なモデルとして、9 世帯の貯蓄が 100 万円、1 世帯の貯蓄が 5000 万円である分布を考えてみます。
# In[4] x = np.full(9, 100) # 貯蓄分布 savings = np.append(x, 5000) print(savings) # [100 100 100 100 100 100 100 100 100 5000]
貯蓄額の中央値と平均値を計算してみます。
# In[5]
# 貯蓄額の中央値と平均値
median_savings = np.median(savings)
mean_savings = np.mean(savings)
print("貯蓄の中央値: {:.1f}".format(median_savings))
print("貯蓄の平均値: {:.1f}".format(mean_savings))
# 貯蓄の中央値: 100.0
# 貯蓄の平均値: 590.0
世帯ごとの貯蓄の平均値が 590 万円と聞いても、実態と随分かけ離れた金額だと感じるはずです。しかし、中央値の 100 万円という数値であれば、この集団の性質をよく表しています。
あるデータにおいて、他の値から大きく外れた値を外れ値とよびます。貯蓄分布の 5000 万は savings における外れ値といえます。データの種類によっては、測定ミスなどで不正なデータが外れ値として混入することもあります。そのような場合、平均値は大きな影響を受けますが、中央値は外れ値にほとんど影響されません。中央値は平均値に比べて不正データに対して頑強な統計値といえます。
statistics.median()
statistics.median() はデータの中央値 (メジアン) を返します。
# PYTHON_STATISTICS_MEDIAN # In[1] import statistics data = [17, 25, 32, 49, 52, 54, 58, 67, 80, 91] # dataの中央値は52と54の平均値 m = statistics.median(data) print(m) # 53.0
statistics.median_low()
statistics.median_low(x) は x の要素が奇数個であるとき、小さい順に数えて中央にくる値を返します。x の要素が偶数個であるときには、中央にある 2 値の小さい方を返します。
# PYTHON_STATISTICS_MEDIAN_LOW
# In[1]
import statistics
data = [3, 8, 15, 20, 29, 36]
median_low = statistics.median_low(data)
print("データの中央値: {:.1f}".format(median_low))
# データの中央値: 15.0
statistics.median_high()
statistics.median_high(x) は x の要素が奇数個であるとき、小さい順に数えて中央にくる値を返します。x の要素が偶数個であるときは、中央にある 2 値の大きい方を返します。
# PYTHON_STATISTICS_MEDIAN_HIGH
# In[1]
import statistics
data = [3, 8, 15, 20, 29, 36]
median_high = statistics.median_high(data)
print("データの中央値: {:.1f}".format(median_high))
# データの中央値: 20.0
numpy.median()
numpy.median() は指定軸に沿った中央値 (メジアン) を返します。
np.median(a, axis=None, out=None, overwrite_input=False, keepdims=False)
axis に 0 を指定する、あるいは axis を省略すると、列ごとの中央値を返します。axis=1 ならば、行ごとの中央値を返します。
# NUMPY_MEDIAN
# In[1]
import numpy as np
x = np.array([[52, 88, 7],
[96, 50, 11],
[40, 51, 84],
[32, 87, 40]])
# 列ごとの中央値
mean_0 = np.median(x, axis=0)
# 行ごとの中央値
mean_1 = np.median(x, axis=1)
print("列ごとの中央値: {}".format(mean_0))
print("行ごとの中央値: {}".format(mean_1))
# 列ごとの中央値: [46. 69. 25.5]
# 行ごとの中央値: [52. 50. 51. 40.]
keepdims に True を渡せば次元を保持します。
# In[2]
# 列ごとの中央値
mean_0 = np.median(x, axis=0, keepdims=True)
# 行ごとの中央値
mean_1 = np.median(x, axis=1, keepdims=True)
print("列ごとの中央値\n{}\n".format(mean_0))
print("行ごとの中央値\n{}".format(mean_1))
'''列ごとの中央値
[[46. 69. 25.5]]
行ごとの中央値
[[52.]
[50.]
[51.]
[40.]]'''
コメント
【プログラミング日記】ドコモオンラインショップで iPhone を買いました。オンラインだと身分証明書とか手数料いらないから気楽ですね。それにしても、車の運転免許証とかマイナンバーカードをもってないと、色々な場面で不便だなと感じることはあります。
ところで、マイナンバーカードって全然普及していないみたいですね。私みたいに手続きを面倒くさがる人が多いのかな。車の免許証があれば事足りるってだけの話かもしれないけど。
まあとにかく、これで、私の IT 機器は PC, iPhone, iPad, ガラケーの 4 機となりました。iPhone と iPad の連携はとってもスムーズです (←当たり前だ)。Wi-Fi なくても、Bluetooth だけで気軽にデータを交換できます。本当は PC も Mac に換えたいんだけど、貧乏だから無理ですね。今使ってる Windows PC が壊れたら考えます。