numpy.save()
numpy.save() を使うと、配列を NumPy 独自のバイナリ形式のファイル (npyファイル) に書き込むことができます。
numpy.save(ファイル名, 配列)
データを書き込むときにはファイルの拡張子を省略できますが、numpy.load() を使って保存したデータを読み込むときには、ファイル名の末尾に .npy を添える必要があります。
# PYTHON_NUMPY_LOAD
import numpy as np
# 配列xを定義
x = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# xをnpyファイルに保存
np.save('my_array', x)
# npyファイルの読み込み
y = np.load('my_array.npy')
print(y)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
numpy.savez()
numpy.savez() を使うと、複数の配列を NumPy 独自の ZIP 形式ファイル (npzファイル) に書き込むことができます。
numpy.savez(ファイル名, 配列1, 配列2, ...)
のように記述すると、配列1 , 配列2, … には、それぞれ ‘arr_0’, ‘arr_1’, … という名前が割り当てられてます。
# PYTHON_NUMPY_SAVE_01
import numpy as np
# 配列xを定義
x = np.array([0, 0, 0])
y = np.array([1, 1, 1])
# xをnpzファイルに保存 (拡張子npzは省略できる)
np.savez('my_data', x, y)
# npzファイルの読み込み (拡張子npzは省略できない)
z = np.load('my_data.npz')
print(z['arr_0'])
print(z['arr_1'])
# [0 0 0]
# [1 1 1]
配列名を自分で指定したい場合は
numpy.savez(ファイル名, キーワード1=配列1, キーワード2=配列2)
のように記述します。
# PYTHON_NUMPY_SAVE_02
import numpy as np
# x=[0 0 0]
x = np.zeros(3, dtype='int32')
# y=[1 1 1]
y = np.ones(3, dtype='int32')
# xをnpzファイルに保存
np.savez('my_data', x=x, y=y)
# xとyのデータを消去
x = []
y = []
# npzファイルをロード
z = np.load('my_data.npz')
print("x = {}".format(z['x']))
print("y = {}".format(z['y']))
# x = [0 0 0]
# y = [1 1 1]
とはいえ、逐一、z[‘x’] のように値を参照するのは面倒なので、実用上はもう一度、z[‘x’] を他の変数に入れ直したほうがよいでしょう。
numpy.savetxt(), numpy.loadtxt()
numpy.savetxt() を使うと、配列データをテキストファイルに書き込むことができます。ただし、書き込めるのは1次元配列と2次元配列のみなので、3次元以上の配列データを保存する場合は numpy.save() や numpy.savez() を使ってください。numpy.loadtxt() を使うとテキストファイルの配列データを読み込むことができます。
データ型の指定
整数型の要素をもつ配列を numpy.savetxt() で保存してから、numpy.loadtxt() で読み込んでみます。
# PYTHON_NUMPY_SAVETXT_01
import numpy as np
# x=[1 1 1]
x = np.ones(3, dtype = 'int32')
# 配列xをテキストファイルに保存
np.savetxt('my_data.txt', x)
# テキストファイルから配列をロード
y = np.loadtxt('my_data.txt')
print(y)
# [1. 1. 1.]
配列をロードすると、各要素が浮動小数点数型になっています。作成された my_data.txt をメモ帳などで開いてみると、次のような形でデータが格納されていることがわかります。
1.000000000000000000e+00 1.000000000000000000e+00 1.000000000000000000e+00
x のデータ型は int32 と指定しておいたにも関わらず、こうした形式で保存されてしまうのは、numpy.savetxt() の fmt というオプション引数のデフォルト値が ‘%.18e’ に設定されているからです (有効桁数が 18 という意味です)。したがって、fmt に ‘%d’ を指定すれば、テキストファイルには整数型で保存されますが、numpy.loadtxt() でこのファイルを読み込むと、データは浮動小数点数型に変換されてしまいます。
# PYTHON_NUMPY_SAVETXT_02
import numpy as np
# x=[1 1 1]
x = np.ones(3, dtype = 'int32')
# 配列xをテキストファイルに保存
np.savetxt('my_data.txt', x, fmt='%d')
# テキストファイルから配列をロード
y = np.loadtxt('my_data.txt')
print(y)
# [1. 1. 1.]
これは numpy.loadtxt() のオプション引数 dtype のデフォルト値が float に設定されているからです。したがって、元の配列と同じデータ型を復元したい場合は、numpy.savetxt() に加えて、numpy.loadtxt() の引数 dtype を指定すればよいことになります。
# PYTHON_NUMPY_SAVETXT_03
import numpy as np
# x=[1 1 1]
x = np.ones(3, dtype = 'int32')
# 配列xをテキストファイルに保存
np.savetxt('my_data.txt', x, fmt='%d')
# テキストファイルから配列をロード
y = np.loadtxt('my_data.txt', dtype='int')
print(y)
# [1 1 1]
デリミタ(区切り文字)の設定
delimiter に任意の文字列を渡して、デリミタ(区切り文字)を設定することができます。numpy.savetxt() のデフォルトのデリミタは半角スペースです。
# PYTHON_NUMPY_SAVETXT_04
import numpy as np
# 3行3列の単位行列
x = np.eye(3)
# 配列xをテキストファイルに保存
np.savetxt('my_data.txt', x, fmt = '%.2e', delimiter = '/')
# テキストファイルから配列をロード
y = np.loadtxt('my_data.txt', delimiter = '/')
print(x)
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
このコードを実行して作成された my_data.txt ファイルを開くと、次のように各要素が ‘/’ で区切られていることがわかります。
1.00e+00/0.00e+00/0.00e+00 0.00e+00/1.00e+00/0.00e+00 0.00e+00/0.00e+00/1.00e+00
numpy.loadtxt() を使って、半角スペース以外のデリミタで区切られたデータを読み込む場合は、delimiter に同じデリミタを指定する必要があります。
CSVファイル
配列を CSV形式のファイルとして保存する場合は、delimiter に “,” を指定します。
# PYTHON_NUMPY_SAVETXT_05
import numpy as np
# x=[1 2 3]
x = np.array([1, 2, 3])
# 配列xをCSVファイルに保存
np.savetxt('my_data.csv', x, fmt = '%d', delimiter = ',')
# CSVファイルから配列をロード
y = np.loadtxt('my_data.csv', dtype = 'int32', delimiter = ',')
print(y)
# [1 2 3]
Excelのデータを読み込む
複雑で大規模なデータは Excel で作成したほうが効率的です。それを CSVファイル(カンマ区切り)として保存してから 構造化配列 として読み込みます (Excel の CSVファイル化についてはこちらのサイトの記事を参照してください)。たとえば、次のような Excel データを my_data_2.csv として保存します。
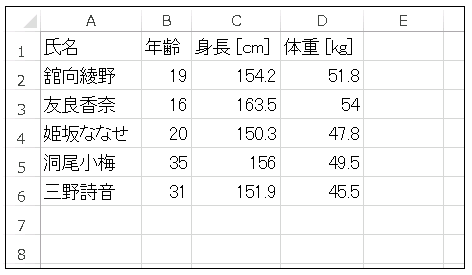
それぞれの項目について、名前を文字列、年齢を整数、身長および体重は浮動小数点数として読み込むためには次のようなコードを記述します。
# PYTHON_NUMPY_SAVETXT_06
import numpy as np
# 複合データ型を定義
# 名前は最大長10のUnicode文字列
# 年齢は1バイト整数(np.int8)
# 身長と体重は半精度浮動小数点数(np.float16)
d = [('name','U16'), ('age','i1'), ('height','f2'), ('weiight','f2')]
# CSVファイルからデータを構造化配列として読み込む
# skiprow = 1で見出しの行をスキップ
x = np.loadtxt('my_data_2.csv', delimiter = ',', dtype = d, skiprows = 1)
print(x)
# [('舘向綾野', 19, 154.2, 51.8) ('友良香奈', 16, 163.5, 54. )
# ('姫坂ななせ', 20, 150.2, 47.8) ('洞尾小梅', 35, 156. , 49.5)
# ('三野詩音', 31, 151.9, 45.5)]
コメント
下記は誤植と思われますので、ご確認ください。
「numpy.savez( )」で、numpy.savez(ファイル名, 配列1, 配列2) → numpy.savez(ファイル名, 配列1, 配列2, …)
配列 1 と配列 2 には → 配列 1, 配列 2, … には
‘ arr_0 ‘, ‘ arr_1 ‘, という → ‘ arr_0 ‘, ‘ arr_1 ‘, … という
numpy.savez(ファイル名, キーワード1=配列1, キーワード2=配列2) →
numpy.savez(ファイル名, キーワード1=配列1, キーワード2=配列2, …)
SAVETEXT_03 プログラムの上の文で、numpy.savetext( ) ではなく → numpy.savetext( ) に加えて、
SAVETEXT_03 プログラムで、np.savetxt(‘my_data.txt’, x) → np.savetxt(‘my_data.txt’, x, fmt = ‘%d’)
ありがとうございます。
直しておきました。m(_ _)m