1 of K 表記法 (one-hot表現)
ニューラルネットワークは、バックプロパゲーションという手法を使って出力値を目標変数(正解値)に近づけるように重みを調整します。ネットワークが分類問題を学習する場合、一般に目標変数は 1 of K (one-hot) 形式で表記されます。
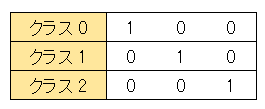
1 of K 表記法は、あるデータが属しているクラス K に等しいインデックスの要素のみを 1 とし、他の要素はすべて 0 とします。たとえば、クラス 2 を 1 of K で表す場合、インデックス 2 の要素を 1 として他の要素は 0 にします。すなわち、 [0 0 1] と表されます(下図参照)。
練習として、Python で 1 of K データを作ってみましょう。
2 次元配列 xm に格納された 1 次元配列データが、それぞれ 1, 0, 2, 1, 0 のクラスに属しているとします。NumPy の identity() 関数 を使うと、クラス番号を要素にもつ配列を 1 of K に変換できます。
# One_of_K
# In[1]
import numpy as np
# データ配列
xm = np.array([[2, 1],
[1, 0],
[1, 2],
[2, 2],
[3, 0]])
# クラス番号を要素にもつ配列を定義
x_class = np.array([1, 0, 2, 1, 0])
# xを3クラスの1-of-K型配列に変換
x_class = np.identity(3, dtype = "int32")[x_class]
print(x_class)
# [[0 1 0]
# [1 0 0]
# [0 0 1]
# [0 1 0]
# [1 0 0]]
機械学習では「あるクラスに属するデータを抜き出す」というコードをよく書きます。データ配列 xm から、クラス 1 に分類されているデータだけを抜き出してみましょう。
# In[2] # クラス1のデータを取り出す x_c1 = xm[x_class[:, 1] == 1] print(x_c1) # [[2 1] # [2 2]]
x_class[:, 1] は x_class からインデックス 1 の列 (左から 2 番目の列) を抜き出します。クラス 1 に属するデータは、この列の要素が 1 となっています。すなわち、x_class[:, 1] == 1 が True と判定されるデータを xm から抜き出せば、クラス 1 に属しているデータ [2 1], [2 2] を取り出すことができます。
出力値のクラス分類
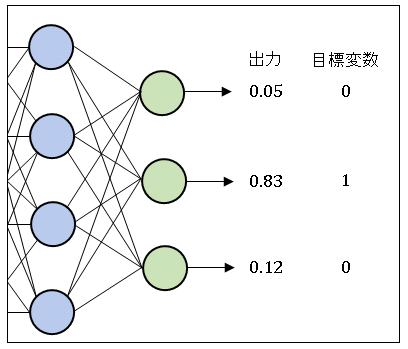
分類問題を扱うニューラルネットワークの出力値 $y_k$ は、入力データがクラス k に分類される確率を表しています。冒頭の図を例にとると、出力値は [0.05, 0.83, 0.12] なので、1 of K 表記法で [0 1 0] となる、すなわちクラス 1 に分類される確率が最も高いことを意味しています(クラス 0 やクラス 2 である可能性も僅かにあります)。そこで、学習を終えた後(交差エントロピー誤差が最小になるように重みパラメータを最適化した後)で出力ベクトルの最大成分を 1 に、他の成分は 0 に置き換えて分類を完了します。
例として ソフトマックス関数 の戻り値を分類してみます。ソフトマックス関数は戻り値の成分をすべて足し合わせると 1 になるという性質をもっています。Python でソフトマックス関数を定義して、戻り値を確認しておきましょう。
# In[3]
# ソフトマックス関数
def softmax(x):
f = np.exp(x)/np.sum(np.exp(x))
return f
x = np.array([1, 2, 4])
y = softmax(x)
s = np.sum(y)
print("戻り値 {}".format(y))
print("戻り値の成分の総和 {}".format(s))
# 戻り値 [0.04201007 0.1141952 0.84379473]
# 戻り値の成分の総和 1.0
numpy.argmax() は配列の最大要素のインデックスを返します。
この関数を使って y のクラスを決定することができます。
# In[4]
# 配列の最大要素のインデックスを取得
y_class = np.argmax(y)
print("データyのクラス:{}".format(y_class))
# データyのクラス:2
最後に numpy.identity() を使って、1 of K 表記法に変換します。
numpy.identity() には整数要素の配列しか渡せないので、予め astype()メソッドを使って y_class の dtype を変更しておきます。
# In[5]
# 配列要素を整数に変換
y_class = y_class.astype("int8")
# 1-of-K表記法に変換
y_class_1ofk = np.identity(3, dtype="int8")[y_class]
print("データyのクラス:{}".format(y_class_1ofk))
# データyのクラス:[0 0 1]
2クラス分類マップ
下図のようなニューラルネットワークを構築して2クラス分類マップを作成してみます。
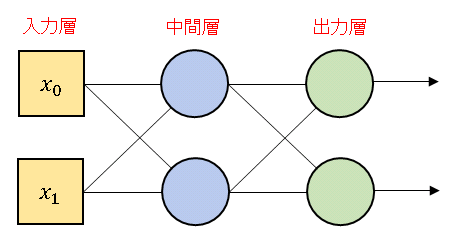
中間層に シグモイド関数、出力層にはソフトマックス関数を組み込みます。今回は NumPy のテクニックを駆使して、for文を一切使わずにコードを書いてみます(一般的にfor構文は処理速度が遅いので可能な限り避けたほうがいいです)。
# In[6]
import matplotlib.pyplot as plt
# 恒等関数
def identity(x):
return x
# シグモイド関数
def sigmoid(x):
f = 1 / (1 + np.exp(-x))
return f
# ソフトマックス関数
def softmax(x):
f = np.exp(x)/np.sum(np.exp(x), axis=1, keepdims=True)
return f
# ニューラルネットワークの層
def layer(xm, wm, func = identity):
dummy = np.ones((xm.shape[0], 1))
xm = np.append(xm, dummy, axis=1)
u = np.dot(xm, wm.T)
return func(u)
# 中間層の重みを設定
wm1 = np.array([[1.0, 2.5, 0.1],
[3.0, 2.0, -0.1]])
# 出力層の重みを設定
wm2 = np.array([[-1.0, 1.5, 0.1],
[ 2.0, -1.0, -0.1]])
# ネットワークへの入力データを設定
x0 = np.linspace(-2, 2, 17)
x1 = np.linspace(-2, 2, 17)
X0, X1 = np.meshgrid(x0, x1)
X0 = X0.reshape(-1)
X1 = X1.reshape(-1)
xm0 = np.vstack([X0, X1]).T
# 出力層への入力行列
xm1 = layer(xm0, wm1, sigmoid)
# ネットワークからの出力行列
xm2 = layer(xm1, wm2, softmax)
# 出力値にクラス番号を割り当てる
xm2 = np.argmax(xm2, axis=1)
# 1-of-Kに変換
xm2 = np.identity(2, dtype="int8")[xm2]
# クラス0に属するデータを抽出
xc_0 = xm0[xm2[:, 0] == 1]
# クラス1に属するデータを抽出
xc_1 = xm0[xm2[:, 0] == 0]
# データをプロット
fig = plt.figure(figsize = (5, 5))
ax = fig.add_subplot(111)
ax.set_xlabel("x0", size=15, labelpad=10)
ax.set_ylabel("x1", size=15, labelpad=10)
ax.set_xlim([-2, 2])
ax.set_ylim([-2, 2])
ax.scatter(xc_0[:, 0], xc_0[:, 1],
marker="D", color="darkorange")
ax.scatter(xc_1[:, 0], xc_1[:, 1],
marker="+", color="darkblue")
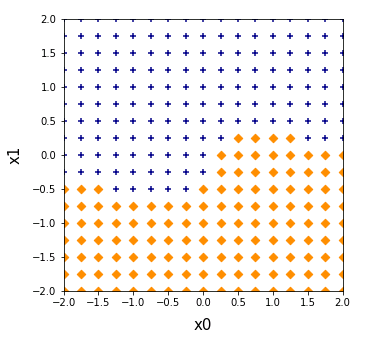 重みパラメータを変更すると色々な模様の図が描かれるので、ぜひ試してみてください。
重みパラメータを変更すると色々な模様の図が描かれるので、ぜひ試してみてください。
コメント
下記は誤植と思われますので、ご確認ください。
In[1] プログラムの下の文で、データ配列 x → データ配列 xm
In[3] プログラムの上の文で、 [0.05, 0,83, 0.12] → [0.05, 0.83, 0.12]
In[3] プログラムで、
f = np.exp(x)/np.sum(np.exp(x), axis = 1, keepdims = True) → f = np.exp(x)/np.sum(np.exp(x))
直しておきました。
ありがとうございます。m(_ _)m