非線形モデル
個々の基底関数が入力データ $x$ 以外の内部パラメータ $p_1,\ p_2,\ p_3,\ …$ を含んでいる場合、これを
\[\phi(x,\ p_1,\ p_2,\ p_3,\ …)\tag{1}\]
と表すことにします。たとえば、ガウス基底の場合は $\mu$ と $\sigma$ が内部パラメータにあたります。線形モデルにおいては基底関数同士の線形結合
\[f(x)=\sum_{k}a_k\phi_k\tag{2}\]
を作り、内部パラメータを固定して $a_k$ についてのみ最適化しました。一方で $a_k$ と内部パラメータをすべて最適化する場合は 非線形モデル になります。
非線形モデルは内部パラメータを自由に調整することで、線形モデルよりも柔軟な関数近似を行なうことができますが、最適化手順を簡潔な数式で表すことが難しい(線形代数では扱えない)ので、一般的には(この講座で最初に扱った)勾配降下法 のアルゴリズムを用いて最適化を行ないます(後述するように、この記事では別の方法を選択します)。
Powell’s method
今回は乱数を使わずに、$\mu$ と $\sigma$ もパラメータとして動かす非線形ガウス基底モデル
\[f(x)=a_0+\sum_{k=1}^{3}a_k\exp\left\{-\frac{(x-\mu_k)^2}{2\sigma_{k}^{2}}\right\}\]
を考えます。前回までのモデルとは異なり、$\mu$ と $\sigma$ の取り得る幅に制限はありません。それぞれの基底関数の中心位置も幅も自在に変えながら重ね合わせて、与えられたデータに最も適合する合計 10 個のパラメータを決定することになります。
これまではライブラリに頼らずにゼロからモデルを構築してきましたが、今回は少し楽をすることにして、Scipy を活用して最適化計算を行なうことにします。
最初に必要なモジュールをインポートしておきます。
# Machine_Learning_06 # In[1] import numpy as np import matplotlib.pyplot as plt from scipy.optimize import minimize
ガウス関数 同士の線形結合、平均二乗誤差関数を定義します。
# In[2]
# ガウス関数を定義
def gauss(x, mu=0, sigma=1):
return np.exp(-(x - mu)**2 / (2*sigma**2))
# ガウス関数の線形結合
# pはリストやタプルで渡す
# p[0],p[1],[2],p[3],p[4],...はa,a1,μ1,σ1,...に対応する10個のパラメータ
def gaussian_basis(x, p):
func = p[0]
for i in range(1, 9, 3):
func += p[i] * gauss(x, p[i+1], p[i+2])
return func
# 平均二乗誤差関数(コスト関数)
def mse_gaussian_basis(p, x, y):
func = gaussian_basis(x, p)
mse = np.mean((func - y)**2)
return mse
scipy.optimize.minimize() を使って、最適化されたパラメータを返す関数を定義します。
# In[3]
# 平均二乗誤差を最小にするパラメータpを返す関数
# 最適化手法としてpowell's methodを指定
def fit_gaussian(p, x, y):
z = minimize(mse_gaussian_basis, p, args=(x, y), method="powell")
return z.x
minimize()関数の第1引数には最小化したい平均2乗誤差関数を渡しています。第2引数にはパラメータベクトルの初期値、args には入力データベクトルと目標データを指定します。method には “powell” を指定していますが、これは最適化手法として Powell’s method (パウエル法) を選択したことを意味します。Powell’s method は勾配降下法を用いずに関数の極値を見つけ出すことのできる手法です。
fit_gaussian() に年齢 x と体重 y のデータを入れて、パラメータを最適化してみます。
# In[4]
# 小数点以下3桁まで表示
np.set_printoptions(precision=3, floatmode="fixed")
# 入力データベクトル
x = np.array([35, 16, 22, 43, 5,
66, 20, 13, 52, 1,
39, 62, 45, 33, 8,
28, 71, 24, 18, 3])
# 目標データベクトル
y = np.array([85.19, 58.93, 64.27, 68.91, 21.27,
68.88, 60.07, 55.18, 88.08, 8.89,
82.31, 81.18, 80.76, 78.98, 37.55,
75.9, 72.39, 69.51, 62.04, 12.47])
# パラメータの初期値
# 10個のパラメータをすべて50に設定しておく
p = np.full(10, 50)
# 平均二乗誤差関数を最小にするようにpを最適化
p = fit_gaussian(p, x, y)
# 最適化されたパラメータベクトルpを表示
print(p)
# [-1.429e+02 1.029e+02 1.779e+01 2.061e+01 1.443e+02 6.406e+01
2.689e+01 6.826e+01 1.076e+02 8.117e+08]
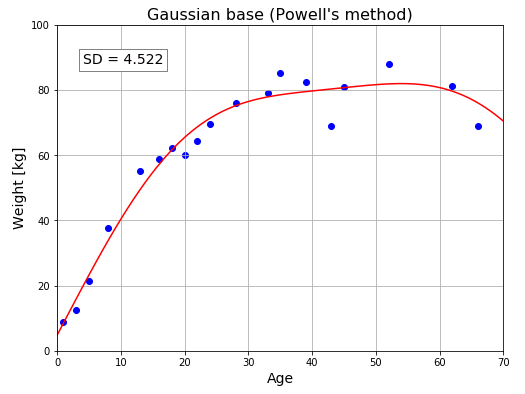
回帰曲線とデータの間の平均二乗誤差と標準偏差を求めてみましょう (曲線がどれぐらいデータにフィットしているかの目安となります)。
# In[5]
# 平均二乗誤差
mse = mse_gaussian_basis(p, x, y)
# 標準偏差
sd = np.sqrt(mse)
print("平均二乗誤差: {:.3f}".format(mse))
print("標準偏差: {:.3f}".format(sd))
# 平均二乗誤差: 20.446
# 標準偏差: 4.522
回帰曲線をプロットしてフィッティングの様子を確認します。
# In[6]
# FigureとAxes
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title("Fitting curve", fontsize = 16)
ax.grid()
ax.set_xlim([0, 70])
ax.set_ylim([0, 100])
ax.set_xlabel("Age", fontsize = 14)
ax.set_ylabel("Weight [kg]", fontsize = 14)
boxdic = {"facecolor" : "white", "edgecolor" : "gray",}
ax.text(4, 88, "SD = {:.3f}".format(sd),
size = 14, linespacing = 1.5, bbox = boxdic)
# 年齢と体重データの散布図
ax.scatter(x, y, color = "blue")
# 回帰曲線をプロット
x2 = np.linspace(0, 70, 100)
y2 = gaussian_basis(x2, p)
ax.plot(x2, y2, color = "red")
plt.show()
4分割交差検証
以前の講座で定義した学習用データとテストデータに分ける関数を再掲します。
# In[7]
# 学習用データとテストデータに分ける関数
def train_test(x, y, k, r):
idx = np.arange(0, x.shape[0])
idx_test = idx[np.fmod(idx, k) == r]
idx_train = idx[np.fmod(idx, k) != r]
x_test = x[idx_test]
x_train = x[idx_train]
y_test = y[idx_test]
y_train = y[idx_train]
return x_train, x_test, y_train, y_test
以下は 4分割交差検証のコードです。
# In[8]
# 分割数
k = 4
# パラメータベクトルの初期値
p_init = np.full(10, 50)
p_train = np.zeros(10)
# 標準偏差の初期値
sd_test = 0
for r in range(k):
x_train, x_test, y_train, y_test = train_test(x, y, k, r)
# パラメータを最適化
p_train = fit_gaussian(p_init, x_train, y_train)
# 現在選択しているテストデータの平均2乗誤差を計算
mse_test = mse_gaussian_basis(p_train, x_test, y_test)
# 現在選択しているテストデータの標準偏差を加算
sd_test += np.sqrt(mse_test)
# 標準偏差の平均値
sd_mean = sd_test / k
print("標準偏差の平均値: {:.3f}".format(sd_mean))
# 標準偏差の平均値: 6.070
【GPT講義】パウエル法のアルゴリズム
パウエル法は非線形最適化問題を解くための手法です。非線形最適化問題とは、目的関数が非線形であり、その関数を最小化または最大化する問題のことを指します。パウエル法は1969年にマイケル・パウエルによって提案されました。この手法は目的関数の勾配情報を必要とせず、目的関数の値のみを利用して最適解を求めることができます。そのため、勾配情報が得られない場合や目的関数が非常に複雑な場合に有用です。
パウエル法のアルゴリズムは以下のようになります。
1. 初期点を設定します。
2. 目的関数の値を計算します。
3. 制約条件を満たすように、新しい点を生成します。
4. 新しい点での目的関数の値を計算します。
5. 目的関数の値が減少している場合、新しい点を採用します。そうでない場合は、古い点を採用します。
6. 収束条件を満たすまで、ステップ3からステップ5を繰り返します。
このように、パウエル法は反復的な手法であり、目的関数の値を最小化する最適解を求めます。また、制約条件を満たすように新しい点を生成するため、制約付き最適化問題にも適用することができます。パウエル法は、機械学習の分野で広く利用されています。例えば、ニューラルネットワークの学習において、重みやバイアスの最適化にパウエル法を適用することがあります。パウエル法の利点としては、勾配情報を必要としないため目的関数が非常に複雑であっても適用可能であることや、制約条件を満たす最適解を求めることができることが挙げられます。しかし、収束までの反復回数が多くなる場合があるため、計算コストが高くなることもあります。
コメント