Irisの品種分類
前回記事で作成した Iris のデータセットを使ってニューラルネットワークに 品種分類 を学習させます。今回構築するネットワークのスペックは以下の通りです。
・入力層のユニット数 : 4
・中間層 1 のユニット数 : 10
・中間層 1 の活性化関数 : ReLU
・中間層 2 のユニット数 : 15
・中間層 2 の活性化関数 : ReLU
・出力層のユニット数 : 3
・バッチサイズ : 15
以下のコードを実行すると、エポックごとに交差エントロピー誤差を計算しながら、300 エポックまで学習を進めます。最後にネットワークにテストデータを入力して出力値とテストデータの一致率を表示します。
# In[19]
# Irisの品種分類
# ネットワークの順伝播関数
def iris_c_forward(data):
mid_1.forward(data)
mid_2.forward(mid_1.y_out)
return out.forward(mid_2.y_out)
# 出力値と正解値データの一致率
def accuracy(output, data_c):
output_class = np.argmax(output, axis = 1)
output_class = np.identity(3, dtype = "int8")[output_class]
argmax_1 = np.argmax(output_class, axis = 1)
argmax_2 = np.argmax(data_c, axis = 1)
count = np.sum(argmax_1 == argmax_2)
acc = count * 100 / n_test
return np.round(acc, 3)
# 乱数を初期化
np.random.seed(11)
# 学習率を設定
alpha = 0.01
# epochを設定
epoch = 300
# データの個数
n_train = data_c_train.shape[0]
n_test = data_c_test.shape[0]
# バッチサイズとバッチ数
b_size = 15
n_batch = n_train // b_size
# インデックス配列
idx = np.arange(n_train)
# 中間層と出力層を作成
mid_1 = Middle_layer(4, 10, ReLU)
mid_2 = Middle_layer(10, 15, ReLU)
out = Output_layer_c(15, 3)
# epoch配列
x = np.arange(epoch)
# 訓練誤差とテスト誤差の初期値
error_train = np.zeros(epoch)
error_test = np.zeros(epoch)
# FigureとAxesを用意
fig = plt.figure(figsize = (6, 6))
ax = fig.add_subplot(111)
ax.grid()
ax.set_xlim(0, epoch)
ax.set_ylim(0, 1.2)
ax.set_xlabel("Epochs", size = 15, labelpad = 10)
ax.set_ylabel("Cross Entropy Error", size = 15, labelpad = 10)
# エポック数だけ学習を繰り返す
for j in range(epoch):
# 全訓練データを学習途中のネットワークに入力して出力を取得
iris_c_forward(data_in_train)
# 全訓練データの平均交差エントロピー誤差
error_train[j] = cross_entropy(out.y_out, data_c_train)
# 全テストデータを学習途中のネットワークに入力して出力を取得
iris_c_forward(data_in_test)
# 全テストデータの平均交差エントロピー誤差
error_test[j] = cross_entropy(out.y_out, data_c_test)
# インデックスをランダムに並べ替える
np.random.shuffle(idx)
# ミニバッチ学習
for k in range(n_batch):
batch = idx[k * b_size : (k + 1) * b_size]
mid_1.forward(data_in_train[batch, :])
mid_2.forward(mid_1.y_out)
out.activate(mid_2.y_out, data_c_train[batch, :])
mid_2.backward(out.y_back)
mid_1.backward(mid_2.y_back)
# 全テストデータを学習途中のネットワークに入力して出力を取得
iris_c_forward(data_in_test)
# 出力値とテストデータの一致率を計算
acc = accuracy(out.y_out, data_c_test)
print("出力値とテストデータの一致率:{}%".format(acc))
ax.plot(x, error_train, color = "blue", label = "train")
ax.plot(x, error_test, color = "red", label = "test")
ax.legend()
# 出力値とテストデータの一致率:97.333%
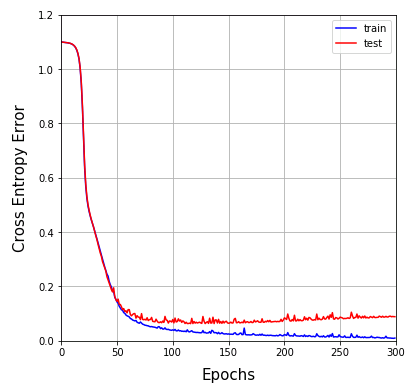
学習が進むにつれて、訓練データの交差エントロピー誤差は順調に下がっていきますが、テストデータの誤差は 100 エポック あたりから停滞し、その後は緩やかに上昇曲線を描きます(ネットワークが訓練データに過度に適応する「過学習」が起きています)。学習は 100 ~ 150 エポックで打ち切ったほうがよいでしょう。
出力値とテストデータの一致率は 300 エポックで 97 % なので、未知のデータに対しても高い精度を持っていますが、ネットワークの構造やハイパーパラメータを変えることで、さらに僅かでも改善が見込めるかもしれません。色々と試してみてください。
コメント