今回からニューラルネットワークを用いた回帰分析を扱います。
回帰分析とは入力値に対して連続的な数値を予測する手法です。
・身長を入力して体重を予測する」
・サイトへのアクセス数を入力して広告収入額を予測する
などが回帰分析の対象となります。分類問題では正解値 (目標変数) は 0 か 1 の値しかとりませんでしたが、回帰分析における出力値はモデルに応じて様々な値をとります。
残差平方和(RSS)
回帰分析では 残差平方和 または 二乗和誤差 とよばれる
\[E=\frac{1}{2}\sum_{j=0}^{m-1}(y_j-t_j)^2\tag{1}\]
を損失関数として用います。英語の residual sum of squares の頭文字をとって RSS とよばれることもあります。$y_j$ と $t_j$ はそれぞれ出力値と正解値です。たとえば 3 成分のベクトルが出力される場合、
\[E=\frac{1}{2}[(y_0-t_0)^2+(y_1-t_1)^2+(y_2-t_2)^2]\tag{2}\]
のように計算します。バッチサイズ が $n$ のとき、すなわち $n$ 個のベクトルをまとめて出力して平均値を計算する場合、ベクトルを横に並べて出力行列と正解行列をつくります。
\[\begin{align*}Y&=\begin{bmatrix}y_{0,0} & y_{0,1} & \cdots & y_{0,n-1}\\y_{1,0} & y_{1,1} & \cdots & y_{1,n-1}\\y_{2,0} & y_{2,1} & \cdots & y_{2,n-1}\\\end{bmatrix}\tag{3}\\[6pt]T&=\begin{bmatrix}t_{0,0} & t_{0,1} & \cdots & t_{0,n-1}\\t_{1,0} & t_{1,1} & \cdots & t_{1,n-1}\\t_{2,0} & t_{2,1} & \cdots & t_{2,n-1}\\\end{bmatrix}\tag{4}\end{align*}\]
次に $Y$ から $T$ を引きます。
\[Y-T=\begin{bmatrix}y_{0,0}-t_{0,0} & y_{0,1}-t_{0,1} & \cdots & y_{0,n-1}-t_{0,n-1}\\y_{1,0}-t_{1,0} & y_{1,1}-t_{1,1} & \cdots & y_{1,n-1}-t_{1,n-1}\\y_{2,0}-t_{2,0} & y_{2,1}-t_{2,1} & \cdots & y_{2,n-1}-t_{2,n-1}\\\end{bmatrix}\tag{5}\]
$Y-T$ のすべての成分の 2 乗について和をとってから、成分の数 $3n$ で割ると、バッチ内における $E$ の平均値を計算できます。$m$ 個の成分をもつ出力ベクトルの場合も同様に考えて、残差平方和を次のように実装することができます。
# 残差平方和(RSS)
# In[1]
import numpy as np
# 残差平方和(RSS)を定義
def rss(y, t):
f = 0.5 * np.sum((y - t)**2) / y.shape[0]
return f
NumPy では 1 次元配列 (横ベクトル) を縦に積んで 2 次元配列をつくるので、(5) の行と列を入れ替えたデータ形式になりますが、残差平方和 (RSS) の演算の性質上、どちらでも結果は同じです。疑似的に出力値 y と正解値 t を設定して動作を確認しておきます。
# In[2]
# 出力値
y = np.array([[4.10 ,4.43, 4.21],
[4.09, 3.85, 4.29],
[3.88, 4.78, 4.93]])
# 正解値(目標変数)
t = np.array([[4.29, 3.76, 4.33],
[3.33, 4.93, 3.69],
[4.98, 3.47, 4.17]])
print("rss: {}".format(rss(y, t)))
# rss: 1.01785
次は バックプロパゲーション に必要な 残差平方和 (RSS) の勾配 を求めてみます。分類のときと同じように、次のようなモデルを考えます。
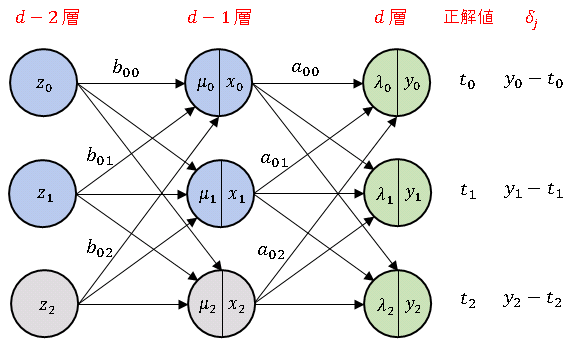
出力層の入力総和 $\boldsymbol{\lambda}$ は
\[\begin{bmatrix}\lambda_0\\ \lambda_1\\ \lambda_2\end{bmatrix}=\begin{bmatrix}a_{00} & a_{01} & a_{02}\\a_{10} & a_{11} & a_{12}\\a_{20} & a_{21} & a_{22}\end{bmatrix}\begin{bmatrix}x_0\\x_1\\x_2\end{bmatrix}\tag{6}\]
と表されます。残差平方和の勾配は
\[\frac{\partial E}{\partial a_{ji}}=\frac{\partial E}{\partial \lambda_{j}}\frac{\partial \lambda_j}{\partial a_{ji}}\tag{7}\]
となります。$\cfrac{\partial \lambda_j}{\partial a_{ji}}$ は分類のときと同じで $x_i$ です。
異なるのは $\cfrac{\partial E}{\partial \lambda_{j}}$ の部分で、
\[\frac{\partial E}{\partial \lambda_{j}}=\frac{\partial E}{\partial y_j}\frac{\partial y_j}{\partial \lambda_{j}}\tag{8}\]
の形で求めます。残差平方和は
\[E=\frac{1}{2}[(y_0-t_0)^2+(y_1-t_1)^2+(y_2-t_2)^2]\tag{9}\]
なので、たとえば $j=0$ のときは
\[\frac{\partial E}{\partial y_0}=y_0-t_0\tag{9}\]
となるので、
\[\frac{\partial E}{\partial \lambda_{0}}=(y_0-t_0)\frac{\partial y_0}{\partial \lambda_{0}}\tag{10}\]
が得られます。同様にして、
\[\frac{\partial E}{\partial \lambda_{j}}=(y_j-t_j)\frac{\partial y_0}{\partial \lambda_j}\tag{11}\]
となるので、
\[\frac{\partial E}{\partial a_{ji}}=\frac{\partial E}{\partial \lambda_{j}}\frac{\partial \lambda_j}{\partial a_{ji}}=x_i(y_j-t_j)\frac{\partial y_j}{\partial \lambda_j}\tag{12}\]
を得ます。層同士の関係を明示するために
\[a_{ji}=w_{ji}^{(d)},\quad x_j=y_j^{(d-1)},\quad \lambda_j=u_j^{(d)}\tag{13}\]
という変数変換を行なうと、
\[\frac{\partial E}{\partial w_{ji}^{(d)}}=y_i^{(d-1)}(y_j-t_j)\frac{\partial y_j}{\partial u_j^{(d)}}\tag{14}\]
この式に学習係数 $\alpha$ を掛けた値が1つ上の中間層の $i$ 番ユニットから出力層の $j$ 番ユニットへの入力値にかかる重みの修正値 $\delta_j$ となります。
損失関数に 交差エントロピー誤差 を用いていた時との違いは $\cfrac{\partial y_j}{\partial u_j^{(d)}}$ の部分です。これは出力層 $j$ 番ユニットの出力値を入力総和で偏微分した値なので、このユニットへの入力総和と出力値が同じであれば $1$ になります。つまり、出力層の活性化関数として恒等関数を設定する (実質的には活性化関数を組込まない) ことで、分類のときと全く同様に回帰分析を実行することができます。このとき、出力層は出力値と正解値の差を上の層に伝達するバックプロパゲーションの役割のみを担うことになります。次回記事ではオプション引数で分類と回帰を選べるような出力層を設計して簡単な回帰分析を実行してみます。
【おすすめ書籍】PythonとKerasによるディープラーニング
新品価格 |  |
ディープラーニングのフレームワーク “Keras” の開発者自らが筆をとり、Python ベースの機械学習とディープラーニングを基礎から丁寧に解説しています。Part1 では機械学習とニューラルネットワークの現況と、ディープラーニングの習得に必要な基礎知識(テンソル演算、勾配降下法、バックプロパゲーション)などを学びます。Part2 では自然言語処理、時系列予測、画像分類、感情分析など、ディープラーニングの実践的な応用について学習します。
コメント