最尤推定(MLE)
次のデータは、2017年11月から2018年1月にかけて、青森県青森市で降水(降雨または降雪)のあった日の最低気温と、降雨・降雪の現象を示すデータです(気象庁が提供しているデータを元に作成しました)。入力データベクトル $\boldsymbol{\mathrm{X}}$ の各要素は気温 (℃)、目標データベクトル $\boldsymbol{\mathrm{T}}$ の各要素は雪 (0) または雨 (1) という現象を表しています ($\boldsymbol{\mathrm{X}}$ の要素は予め気温について昇順ソートされています)。ただし、雪と雨がともに観測された場合は雪 (0) に分類してあります。気象庁が提供する「現象なし」のデータは現象が観測されなかった場合を 1、観測された場合を 0 で表現します。要するに僅かでも雪が降った場合は 0 に分類されるということです。
# Rain_or_Snow
# In[1]
# モジュールをインポート
import numpy as np
import matplotlib.pyplot as plt
# 青森県青森市の気象観測データ(2017年11月~2018年1月)
# 最低気温
X = np.array([-6.5, -6.2, -6.1, -5.9, -5.3, -5.2, -5.2, -4.8,
-4.5, -4.1, -4.1, -3.9, -3.9, -3.7, -3.6, -3.6,
-3.5, -3.5, -3.4, -3.0, -2.9, -2.8, -2.7, -2.7,
-2.6, -2.5, -2.5, -2.4, -2.3, -2.0, -2.0, -1.9,
-1.8, -1.6, -1.3, -1.2, -1.2, -1.0, -1.0, -1.0,
-0.9, -0.9, -0.9, -0.9, -0.8, -0.5, 0.0, 0.1,
0.1, 0.2, 0.2, 0.3, 0.4, 0.5, 1.1, 2.1,
4.3, 4.3, 4.9, 5.5, 6.5, 7.1, 7.5, 7.8])
# 降雪/降雨現象(雪=0,雨=1)
T = np.array([0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 0,
0, 1, 1, 1, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1])
Matplotlib を使って、このデータをプロットしてみましょう。
# In[2]
# FigureとAxesの設定
fig, ax = plt.subplots(figsize=(8, 5))
ax.grid()
ax.set_xlim(-8, 8)
ax.set_ylim(-0.5, 1.5)
ax.set_yticks([0, 1])
ax.set_xlabel("Temperature [${}^\circ$C]", fontsize=14)
# 雨は赤色、雪は青色の点で表示
ax.scatter(X[T == 0], T[T == 0], color="blue",
s=16, label="snow", zorder=2)
ax.scatter(X[T == 1], T[T == 1], color="red",
s=16, label="rain", zorder=2)
# Tが1となるXの要素で配列を生成し、その中から最小要素を抽出
Z = X[T == 1]
x_1 = np.min(Z)
# Tが1となるXの要素で配列を生成し、その中から最大要素を抽出
Z = X[T == 0]
x_2 = np.max(Z)
# Tが0と1の両方を取り得る範囲を塗り潰す
ax.axvspan(x_1, x_2, color="orange", alpha=0.4, zorder=1)
# x軸の目盛を設定
xt = range(-8, 9, 4)
xt = list(xt) + [x_1, x_2]
ax.set_xticks(xt)
ax.legend()
plt.show()
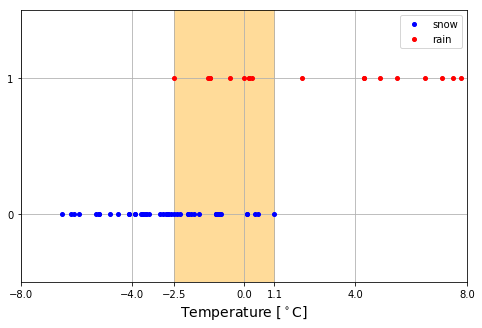
グラフを見ると、最低気温が 2.1℃以上なら雨、-2.5℃以下なら雪となっています。しかし、気温が-2.5℃ ~ 1.1℃の範囲内(薄いオレンジ色で塗られている範囲)では、同じ気温であっても、日によって雨のときもあれば雪のときもあります。実際、降雪条件は湿度や上層の気温、観測点の置かれた場所の地形など、他の様々な要因が絡むので、地上の最低気温だけで決定できるものではありません。それでも最初は敢えて問題を単純化して、地上最低気温だけを入力変数として与えて、降雪の有無を予測することを試みます。
最終的な目標は、未知の気温データ $x$ を与えたときに、それぞれのクラス(雪または雨)に分類することです。ただし、この分類は「雪になる確率が高い」または「雨になる確率が高い」というような曖昧さを含めた情報になります。天気予報でおなじみの表現ですね。
ある気温 $x$ において、$t$ が $1$ の値となる(すなわち雨となる)確率を
\[P(t=1|x)\tag{1}\]
と表すことにします。たとえば手持ちのデータを見る限り、$x\gt 2$ であれば必ず雨になっているので、
\[P(t=1|5)=1\tag{2}\]
であることは言えそうです。もちろん、これは絶対にそうだと言い切れるものではありません。この年に観測されたデータが偶然そうなっていただけで、別の年に観測すれば気温 5℃でも雪となる可能性もあるからです。あくまで手持ちのデータから、$P(t=1|5)=1$ と推定できるというだけです。
雨と雪が重なっている範囲内については、気温が高くなるほど雨になる確率が高くなるはずです。つまり、この範囲内で確率は $0$ から $1$ へと遷移するので、$f(x)=P(t=1|x)$ は、おおよそ $(x,t)=(-2.5,\ 0)$ と $(x,t)=(1,\ 1)$ を結ぶような曲線となっているはずです。
そこで、このような観測データを得るに至った「最もありえそうな曲線の形」を探すことにします。このように曖昧な表現をするのは、観測データ $(x,t)$ は、下限 $0$, 上限 $1$ という条件を満たすなら、どのような確率曲線からでも得られる可能性があるからです。
私たちは観測データを元に確率を「推測」することしかできません。
たとえば、サイコロを $120$ 回投げて $1$~$6$ の目が出た回数がそれぞれ
\[19,\ 21,\ 20,\ 22,\ 17,\ 21\]
となったときに、どの目もおおよそ $1/6$ の確率で出現すると推測します。しかし、この推測は間違っているかもしれません。目の出方に偏りのあるサイコロを振って、たまたま均等に近い分布になったかもしれないからです。しかし、それぞれの目が出る確率が $1/6$ である可能性が最も高いといえます。
このように、ある一組のデータを生成する確率 $P$ を 尤度 とよび、その中で最も可能性の高い確率(尤度の最大値)を探し出すことを 最尤推定 (MLE : maximum likelihood estimation) または 最尤法 (method of maximum likelihood) とよびます。「尤(ゆう)」という字は「すぐれている」という意味があるので、「最尤推定」とは「最も適切な推定」ということになります。英語では likelihood (ありそうな) という単語が使われていますね。
とはいえ、(これは線形回帰でも同じでしたが)無数にある関数の中から最適なものを見つけることは不可能なので、とりあえず一つの関数を決めて、その関数のパラメータを調整することによって最適化を図ります。それでは、モデルとしてどのような関数を選べば良いのかという話になりますが、これは案外難しい問題です。扱う現象によって適切な関数は異なるので、その時々で色々と試行錯誤するしかありません。
たとえば、雪 (0) と雨 (1) が重なる範囲を直線で表すのはどうでしょう?
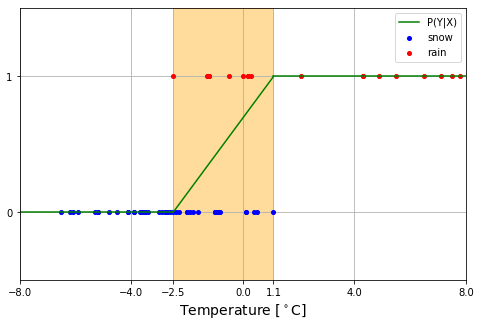
雨 (1) となる確率が気温に比例して増加することは十分にありそうな話です。しかし、そうではないかもしれないので、直線的単調増加の性質をもちながらも、パラメータによって、ある程度形状を自由に変化させられるシグモイド関数を考えてみます。
\[\sigma(x)=\frac{1}{1+e^{-ax}}\quad (a\gt 0)\tag{3}\]
この関数はゲインとよばれるパラメータ $a$ の値によって次のように形を変えます。
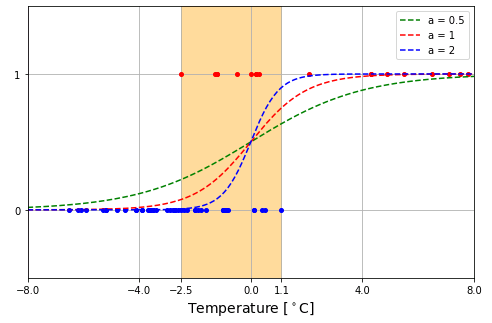
しかし、この図を見て分かるように、シグモイド関数 は勾配を変えることはできますが、中心位置が $x=0$ のところに固定されていて、左右にスライドさせることはできません。そこで、$ax$ を $ax+b$ で置き換えた ロジスティック関数
\[L(x)=\sigma(ax+b)=\frac{1}{1+\exp\{-(ax+b)\}}\tag{4}\]
を考えます。こうすると曲線を左右に平行移動させながら、より自在にデータに適合させることができるようになります。
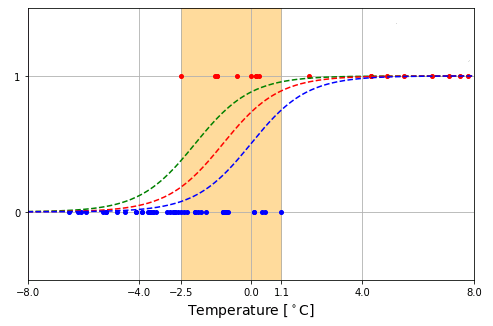
とりあえず、ロジスティック関数を採用することにしましょう。
すなわち目標変数 $t$ は
\[P(t=1|x)=L(x)=\frac{1}{1+\exp\{-(ax+b)\}}\tag{5}\]
にしたがって生成されたと仮定して、2 個のパラメータ $a$ と $b$ を最適化することを目標にします(ロジスティック回帰は単純なモデルですが、多くの現象を説明できることが知られています)。次回記事では「交差エントロピー誤差」という新しい概念を導入します。
コメント
In[1] プログラムの上の文で、
「したがって、より厳密に表現するならば、目標データベクトルの各要素は降水現象があった日の「降雪現象なし」を意味します。」の意味がよくわかりません。なくてもいいような気がします。
In[2] プログラムで初めて知ったことが 2 つありました。
X[ T == 1 ] というように、他の配列の要素の条件を満足するインデックスをそのまま利用できる。
set_xticks( ) に渡す目盛りのリストの要素の順番は任意でよい。
In[2] プログラムの下の文で、2℃以上 → 2.1℃以上
「したがって、より厳密に … 」のくだりは、確かに自分自身で読み返しても意味不明でした。申し訳ないです。削除しておきました。
X[T==1] はマスキング操作の一種です。たとえば、以下のように配列 arr_1 と arr_2 を定義したとします。
◆◆◆◆◆
# In[1]
import numpy as np
arr_1 = np.array([0, 1, 0, 1, 1])
arr_2 = np.array([“a”, “b”, “c”, “d”, “e”])
◆◆◆◆◆
このとき、arr_1==1 という記述でブール配列が生成されます。
◆◆◆◆◆
# In[2]
print(arr_1==1)
# [False True False True True]
◆◆◆◆◆
NumPy の任意の配列にブール配列を渡すと、True のインデクスに該当する要素だけが抽出されます。
◆◆◆◆◆
# In[3]
print(arr_2[arr_1==1])
# [‘b’ ‘d’ ‘e’]
◆◆◆◆◆
マスキング操作についての詳細は「ブール配列とマスキング操作」の記事で書いているので、ぜひご確認ください。