重みの更新式の意味
今回は前回記事で得たバックプロパゲーションにおける 重みの更新式 の意味を考えます。
出力層の重み更新式
$d-1$ 層 $i$ 番ニューロンから $d$ 層 $j$ 番ニューロンに入力される信号に掛かる重み $w_{ji}^{(d)}$ は以下の規則で更新されます。
\[w_{ji}^{(d)}(t+1)=w_{ji}^{(d)}(t)-\alpha\delta_jy_i^{(d-1)}\tag{1}\]
$\delta_j$ は出力値 $y_j$ と正解値(目標変数)$t_j$ の誤差 $y_j-t_j$ として定義されています。
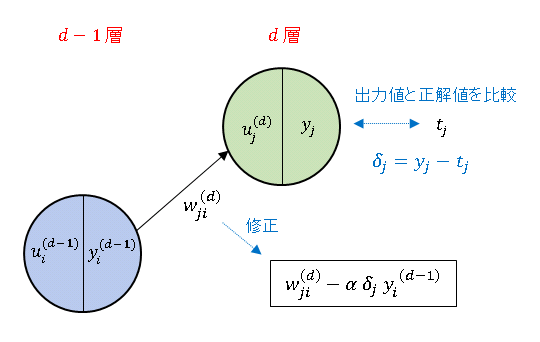
学習率 $\alpha$ は正の値に設定します。一般に中間層の活性化関数 (シグモイド関数 や RELU 等) は正の値をとるので、$y_i^{(d-1)}$ も正です。
したがって、仮に $\delta_j=y_j-t_j\gt 0$ であったなら(すなわち出力値が正解値より大きい場合は)、重みを現在の値よりも小さく修正して入力信号を絞ります。
逆に $\delta_j=y_j-t_j\lt 0$ のときは(出力値が正解値より小さい場合は)、重みを大きく修正して入力信号を強めます。また、その修正幅は誤差 $\delta_j=y_j-t_j$ と入力信号 $y_i^{(d-1)}$ に比例します。
出力層と1つ上の中間層のニューロン数がそれぞれ $3$ 個、$2$ 個である場合を考えて、すべての重みの更新式を書き下すと
\[\begin{align*}&\begin{bmatrix}w_{00}(t+1) & w_{01}(t+1) & w_{02}(t+1)\\w_{10}(t+1) & w_{11}(t+1) & w_{12}(t+1)\\w_{20}(t+1) & w_{21}(t+1) & w_{22}(t+1)\end{bmatrix}^{(d)}\\[6pt]&=\begin{bmatrix}w_{00}(t) & w_{01}(t) & w_{02}(t)\\w_{10}(t) & w_{11}(t) & w_{12}(t)\\w_{20}(t) & w_{21}(t) & w_{22}(t)\end{bmatrix}^{(d)}-\alpha \begin{bmatrix}\delta_0y_0 & \delta_0y_1 & \delta_0y_2\\\delta_1y_0 & \delta_1y_1 & \delta_1y_2\\\delta_2y_0 & \delta_2y_1 & \delta_2y_2\end{bmatrix}^{(d-1)}\tag{2}\end{align*}\]
となります。各成分の層番号 $(d)$、$(d-1)$ は省略し、代わりに行列の右上に添えてます。重みの修正部分は
\[-\alpha \begin{bmatrix}\delta_0 \\ \delta_1 \\ \delta_2\end{bmatrix}\begin{bmatrix}y_0 & y_1 & y_2\end{bmatrix}^{(d-1)}\tag{3}\]
のように書くことができます。ここで、バッチサイズ 3 のデータを入力することを考えます。バッチ内の各々のデータの損失関数を $E_0,\ E_1,\ E_2$ とすると、損失関数の勾配の平均値は
\[\frac{1}{3}\left(\frac{\partial E_0}{\partial w_{ji}^{(d)}}+\frac{\partial E_1}{\partial w_{ji}^{(d)}}+\frac{\partial E_2}{\partial w_{ji}^{(d)}}\right)\tag{4}\]
で与えられます (バッチサイズとエポックの記事を参照)。更新式に代入すると $1/3$ の部分は学習率 $\alpha$ に吸収されるので無視します。誤差と出力値の右下にバッチ番号を添えると、ステップごとの重みの修正値は
\[-\alpha(\delta_{j0}y_{i0}^{(d-1)}+\delta_{j1}y_{i1}^{(d-1)}+\delta_{j2}y_{i2}^{(d-1)})\tag{5}\]
と書くことができます。これを行列で表すと次のようになります。
\[-\alpha \begin{bmatrix}\delta_{00} & \delta_{01} & \delta_{02}\\\delta_{10} &\delta_{11} & \delta_{12}\\\delta_{20} & \delta_{21} & \delta_{22}\end{bmatrix}\begin{bmatrix}y_{00} & y_{10} & y_{20}\\y_{01} & y_{11} &y_{21}\\y_{02} & y_{12} & y_{22}\end{bmatrix}^{(d-1)}=DY^{(d-1)}\tag{6}\]
Python で実装する場合は、誤差 $\delta_{ji}$ は 1 次元配列を縦積みした 2 次元配列形式で保存するので、その配列を $\mathrm{delta}$ で表すと、$D=\mathrm{delta}^T$ となります ($T$ は転置をとることを意味します)。
中間層の重み更新式
$d-1$ 層 $i$ 番ニューロンから $d$ 層 $j$ 番ニューロンに入力される信号に掛かる重み $w_{ji}^{(d)}$ の更新は次式で与えられます。
\[w_{ji}^{(d-1)}(t+1)=w_{ji}^{(d-1)}(t)-\alpha\delta_j^{(d-1)}y_i^{(d-2)}\tag{7}\]
ただし、$\delta_j^{(d-1)}$ は
\[\delta_j^{(d-1)}=f'(u_j^{(d-1)})\sum_{r}w_{rj}^{(d)}\delta_r\tag{8}\]
によって定義されます。$\displaystyle\sum_{r}w_{rj}^{(d)}\delta_r$ の部分は $\delta_j$ の線形結合ですから、下の図にあるように、誤差の情報を中間層まで遡って伝えていることになります。
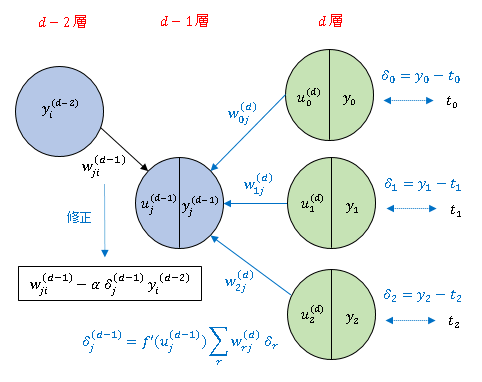
出力層の更新式 (1) と対応させて、$\delta_j^{(d-1)}$ を $d-1$ 層 $j$ 番ニューロンの誤差と考えます。$f'(u_j^{(d-1)})$ は活性化関数の微分を表しています。さらに上の層の重みの更新式は、この $\delta_j^{(d-1)}$ を寄せ集めて作られることになります。
コメント
下記は誤植と思われますので、ご確認ください。
(6) 式の Y 行列の (0から数えて) 1 行目 2 列目の要素で、y12 → y21
修正しました。
ありがとうございます。m(_ _)m